{
"experiment_name": "string (required)",
"experiment_description": "string (optional)",
"experiment_start_time": "datetime (required)",
"experiment_end_time": "datetime (required)",
"dataset_id": "uuid (optional - an external dataset id, used to group experiments together)",
"dataset_name": "string (optional - must provide either dataset_id or dataset_name)",
"dataset_description": "string (optional)",
"experiment_metadata": { // Object (any shape - optional)
"key": "value"
},
"summary_experiment_scores": [ // List of summary feedback objects (optional)
{
"key": "string (required)",
"score": "number (optional)",
"value": "string (optional)",
"comment": "string (optional)",
"feedback_source": { // Object (optional)
"type": "string (required)"
},
"feedback_config": { // Object (optional)
"type": "string enum: continuous, categorical, or freeform",
"min": "number (optional)",
"max": "number (optional)",
"categories": [ // List of feedback category objects (optional)
{
"value": "number (required)",
"label": "string (optional)"
}
]
},
"created_at": "datetime (optional - defaults to now)",
"modified_at": "datetime (optional - defaults to now)",
"correction": "Object or string (optional)"
}
],
"results": [ // List of experiment row objects (required)
{
"row_id": "uuid (required)",
"inputs": { // Object (required - any shape). This will
"key": "val" // be the input to both the run and the dataset example.
},
"expected_outputs": { // Object (optional - any shape).
"key": "val" // These will be the outputs of the dataset examples.
},
"actual_outputs": { // Object (optional - any shape).
"key": "val" // These will be the outputs of the runs.
},
"evaluation_scores": [ // List of feedback objects for the run (optional)
{
"key": "string (required)",
"score": "number (optional)",
"value": "string (optional)",
"comment": "string (optional)",
"feedback_source": { // Object (optional)
"type": "string (required)"
},
"feedback_config": { // Object (optional)
"type": "string enum: continuous, categorical, or freeform",
"min": "number (optional)",
"max": "number (optional)",
"categories": [ // List of feedback category objects (optional)
{
"value": "number (required)",
"label": "string (optional)"
}
]
},
"created_at": "datetime (optional - defaults to now)",
"modified_at": "datetime (optional - defaults to now)",
"correction": "Object or string (optional)"
}
],
"start_time": "datetime (required)", // The start/end times for the runs will be used to
"end_time": "datetime (required)", // calculate latency. They must all fall between the
"run_name": "string (optional)", // start and end times for the experiment.
"error": "string (optional)",
"run_metadata": { // Object (any shape - optional)
"key": "value"
}
}
]
}


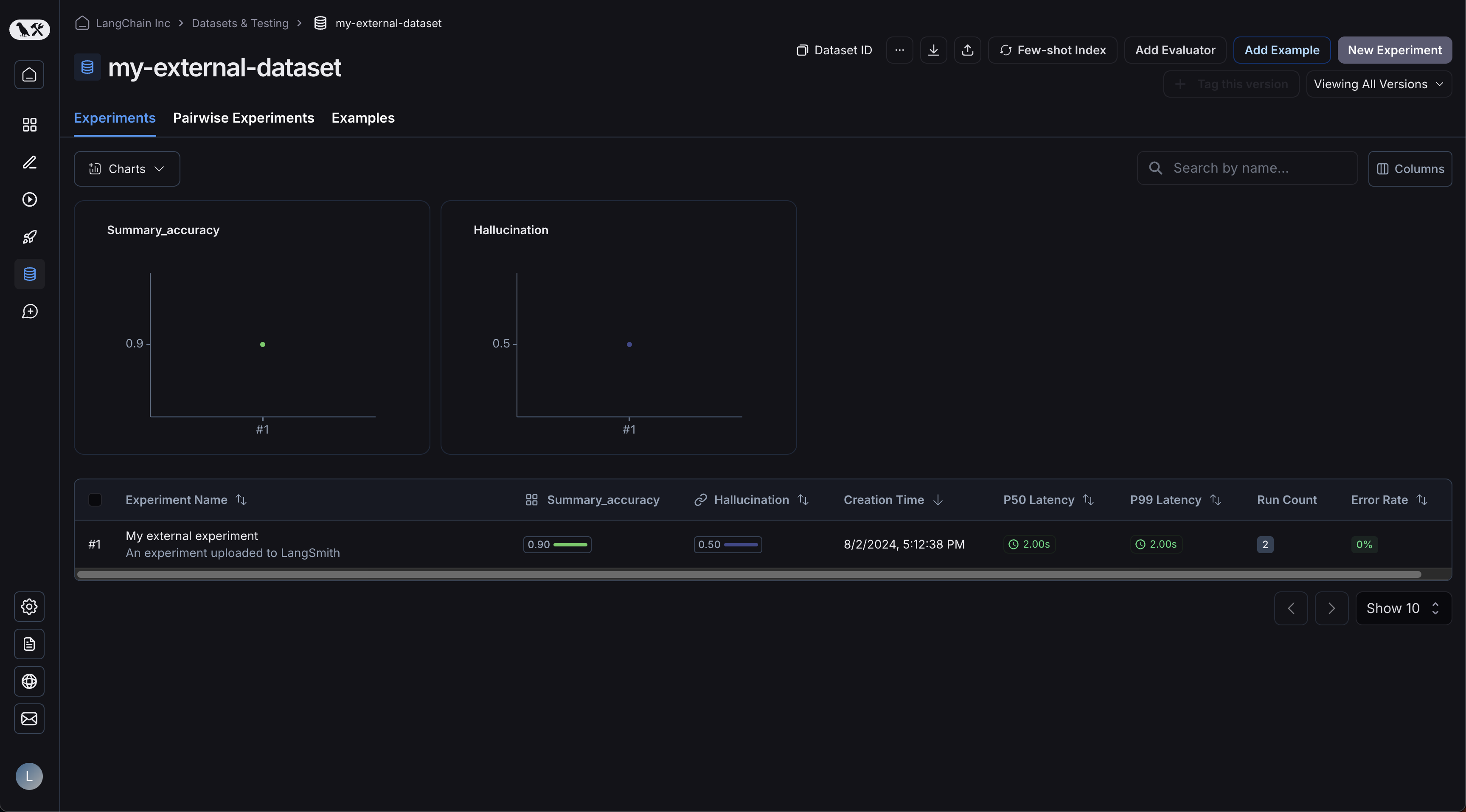 예제들이 업로드되어 있습니다:
예제들이 업로드되어 있습니다: 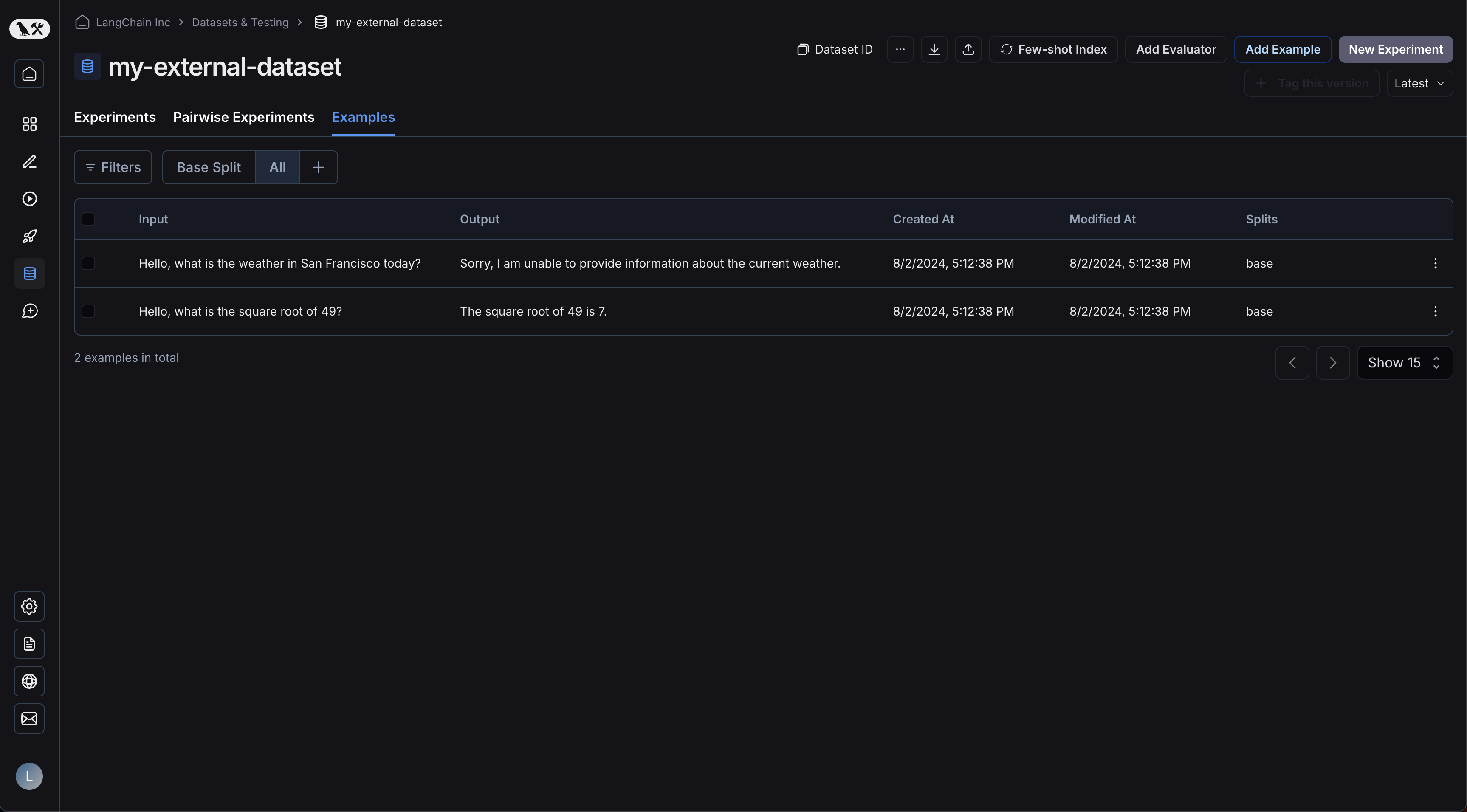 실험을 클릭하면 비교 뷰로 이동합니다:
실험을 클릭하면 비교 뷰로 이동합니다: 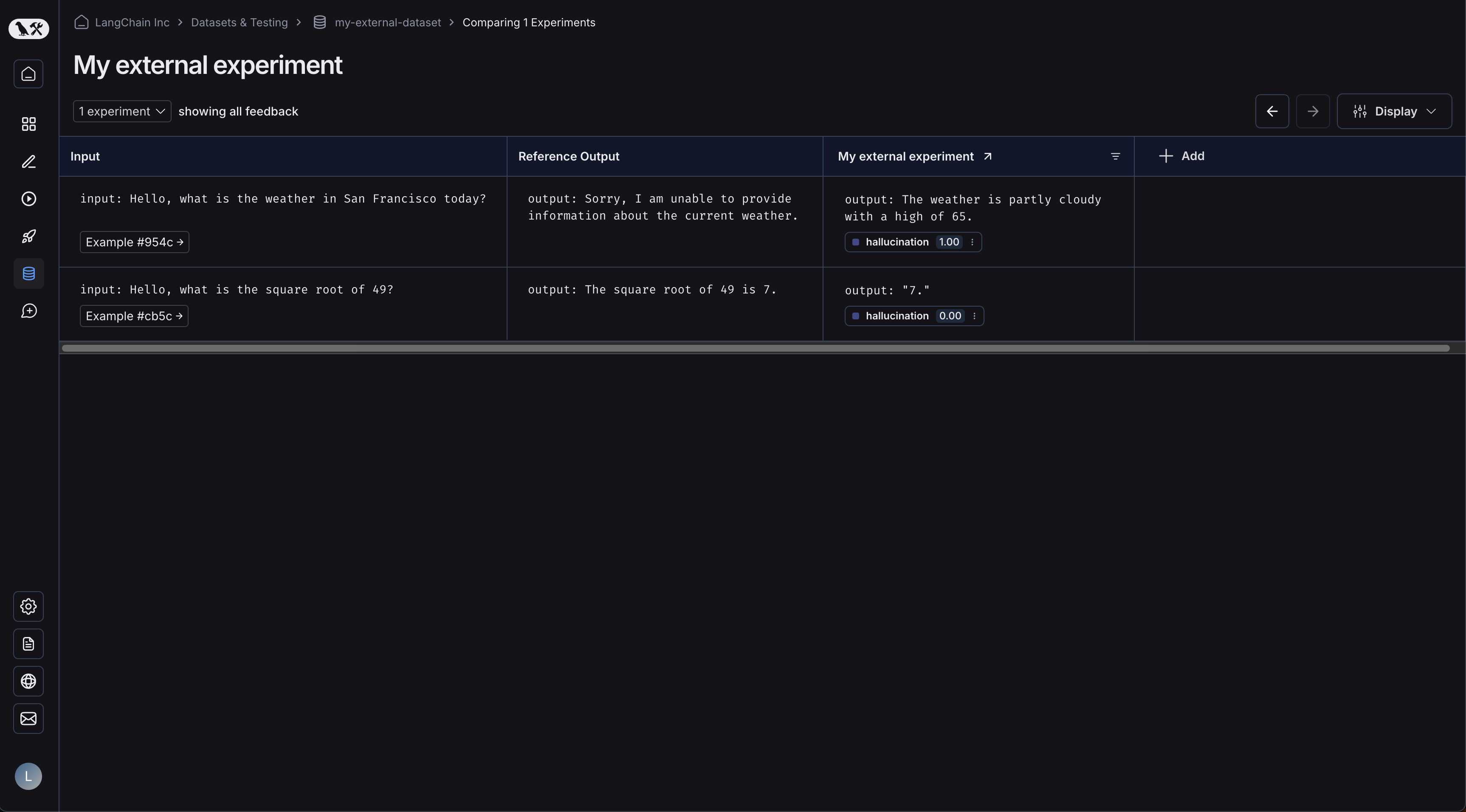 데이터셋에 더 많은 실험을 업로드할수록 비교 뷰에서 결과를 비교하고 회귀를 쉽게 식별할 수 있습니다.
데이터셋에 더 많은 실험을 업로드할수록 비교 뷰에서 결과를 비교하고 회귀를 쉽게 식별할 수 있습니다.