- 데이터셋: 테스트 입력(및 선택적으로 예상 출력) 세트입니다.
- 대상 함수: 테스트하려는 애플리케이션의 일부로, 단일 LLM 호출, 하나의 모듈 또는 전체 워크플로일 수 있습니다.
- 평가자: 대상 함수의 출력을 점수화하는 함수입니다.
사전 요구 사항
시작하기 전에 다음 사항을 확인하세요:- LangSmith 계정: smith.langchain.com에서 가입하거나 로그인하세요.
- LangSmith API 키: API 키 생성 가이드를 따르세요.
- OpenAI API 키: OpenAI 대시보드에서 생성하세요.
- UI
- SDK
1. 워크스페이스 시크릿 설정
In the LangSmith UI, ensure that your OpenAI API key is set as a workspace secret.- Navigate to Settings and then move to the Secrets tab.
- Select Add secret and enter the
OPENAI_API_KEYand your API key as the Value. - Select Save secret.
When adding workspace secrets in the LangSmith UI, make sure the secret keys match the environment variable names expected by your model provider.
2. 프롬프트 생성
LangSmith의 프롬프트 플레이그라운드를 사용하면 다양한 프롬프트, 새로운 모델 또는 다양한 모델 구성에 대해 평가를 실행할 수 있습니다.- LangSmith UI에서 Prompt Engineering 아래의 Playground로 이동합니다.
-
Prompts 패널에서 system 프롬프트를 다음과 같이 수정합니다:
Human 메시지는 그대로 둡니다:
{question}.
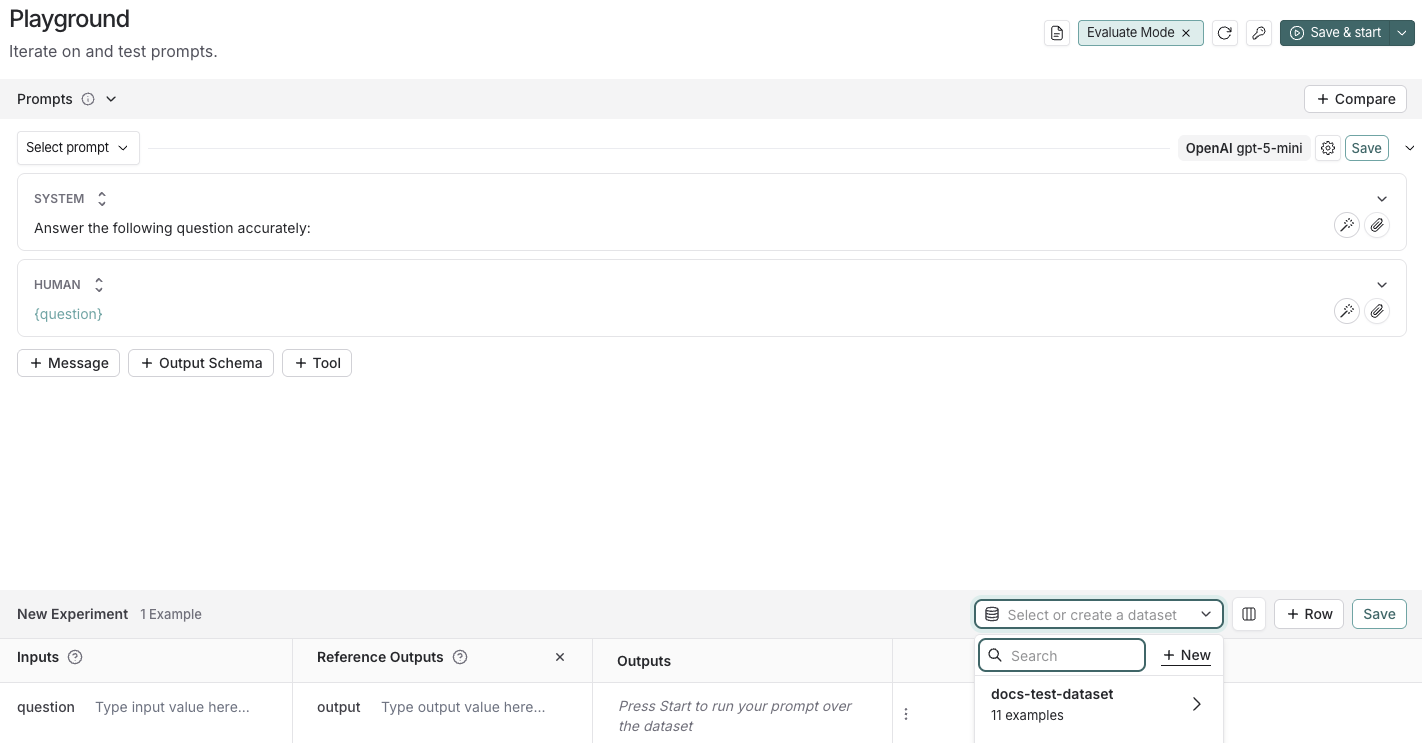
3. 데이터셋 생성
- Set up Evaluation을 클릭하면 페이지 하단에 New Experiment 테이블이 열립니다.
-
Select or create a new dataset 드롭다운에서 + New 버튼을 클릭하여 새 데이터셋을 생성합니다.
-
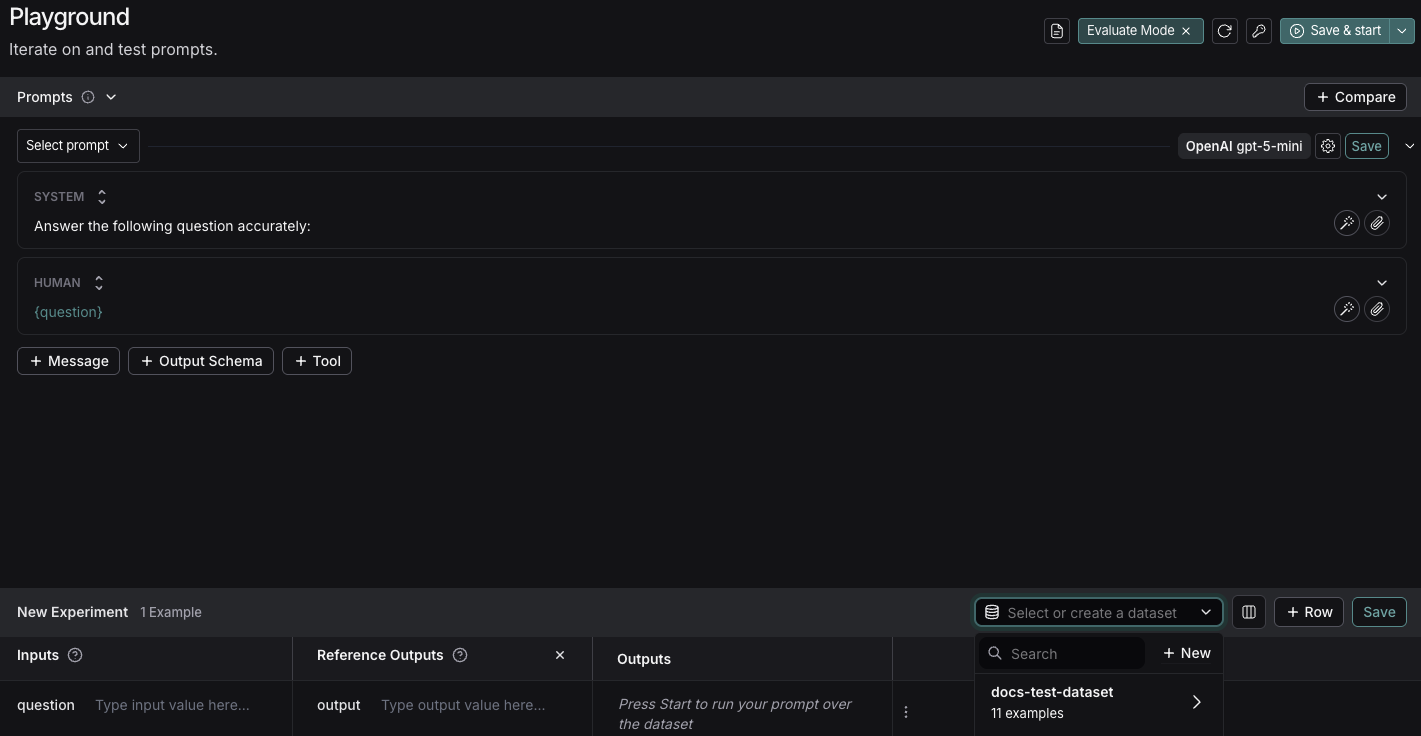
데이터셋에 다음 예제를 추가합니다:
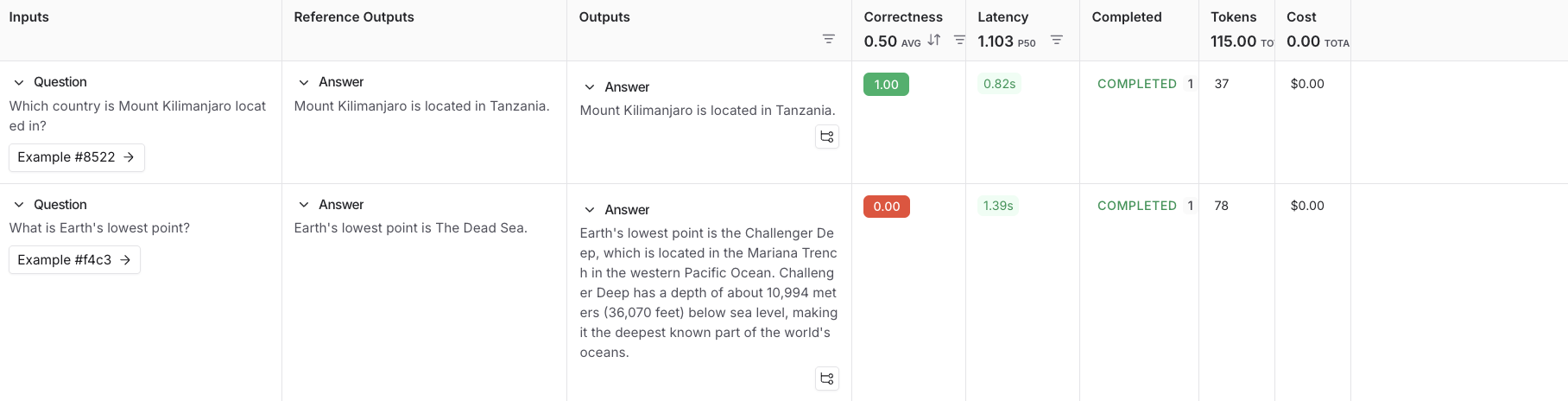
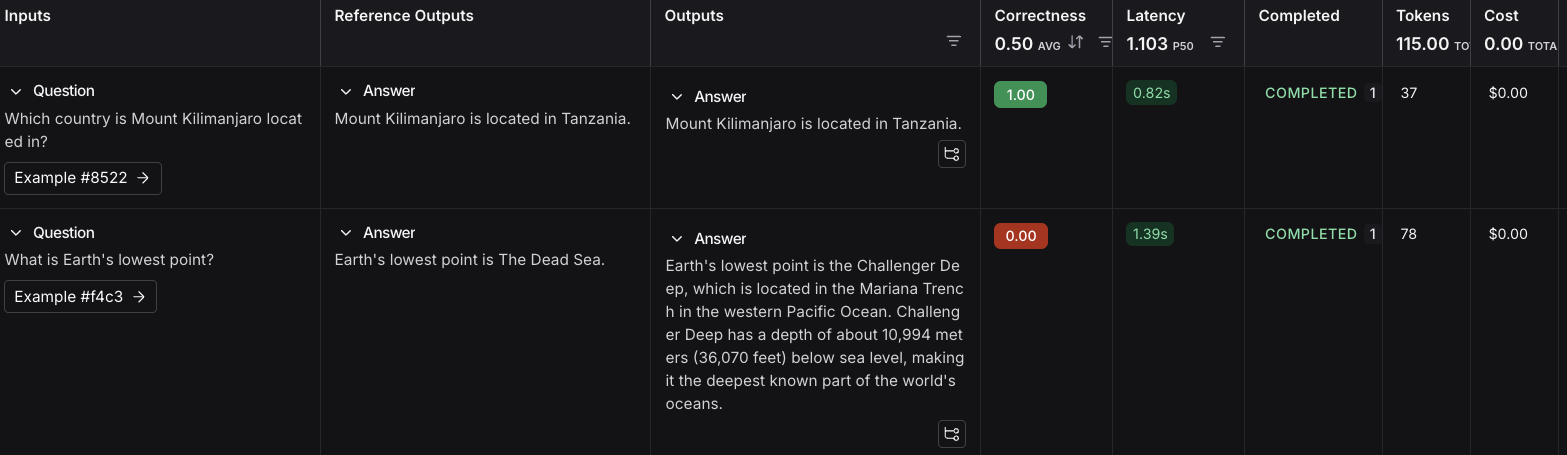
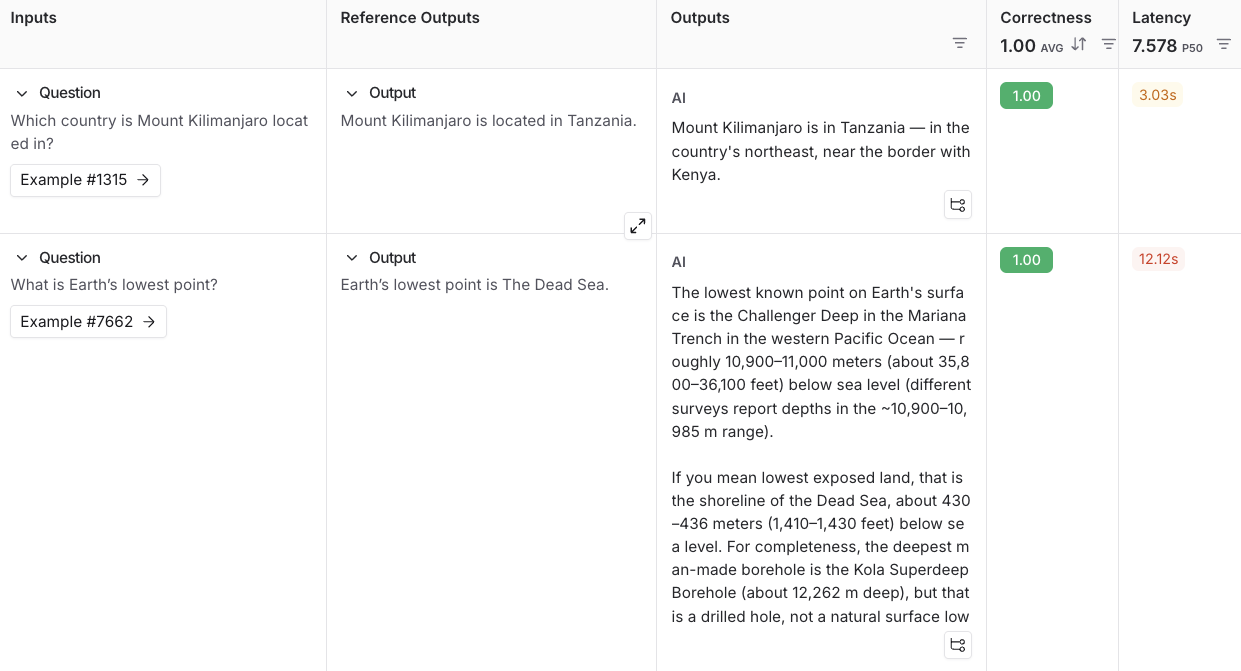
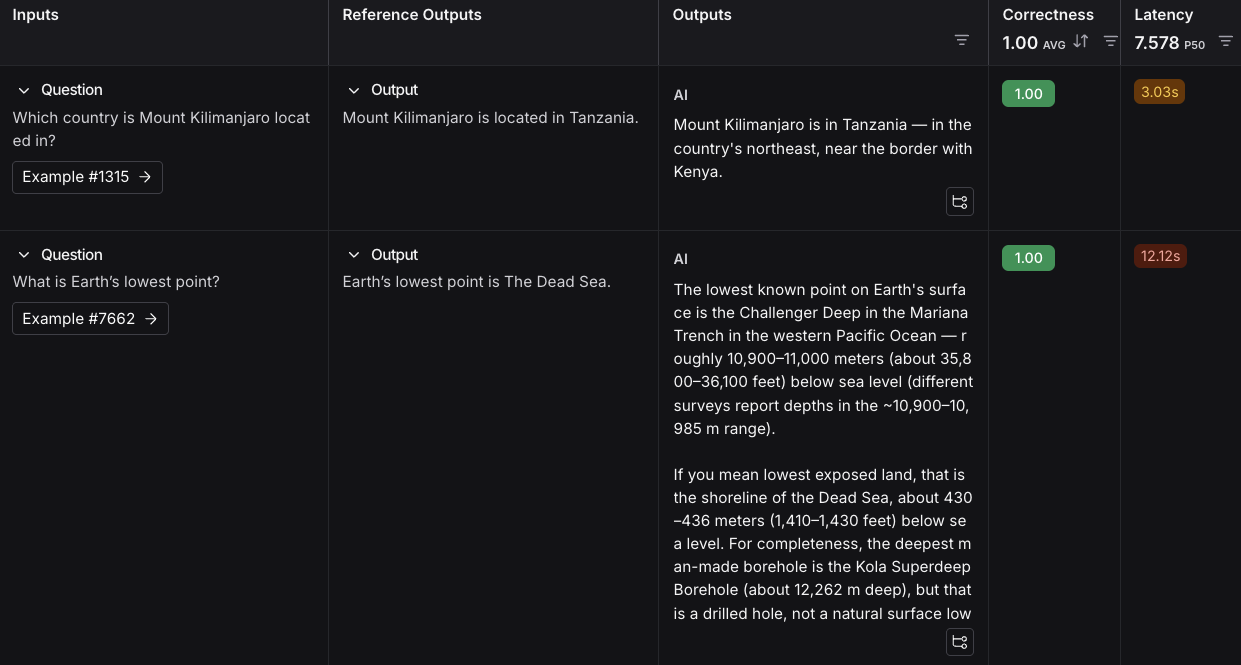
Inputs Reference Outputs question: Which country is Mount Kilimanjaro located in? output: Mount Kilimanjaro is located in Tanzania. question: What is Earth’s lowest point? output: Earth’s lowest point is The Dead Sea. - Save를 클릭하고 이름을 입력하여 새로 생성한 데이터셋을 저장합니다.
4. 평가자 추가
- + Evaluator를 클릭하고 Pre-built Evaluator 옵션에서 Correctness를 선택합니다.
- Correctness 패널에서 Save를 클릭합니다.
5. 평가 실행
-
오른쪽 상단의 Start를 선택하여 평가를 실행합니다. 이렇게 하면 New Experiment 테이블에 미리보기가 포함된 실험이 생성됩니다. 실험 이름을 클릭하면 전체 보기를 볼 수 있습니다.
다음 단계
- 평가에 대한 자세한 내용은 평가 문서를 참조하세요.
- UI에서 데이터셋 생성 및 관리하는 방법을 알아보세요.
- 프롬프트 플레이그라운드에서 평가 실행하는 방법을 알아보세요.