데이터셋 생성 및 예제 추가
다음 섹션에서는 LangSmith에서 데이터셋을 생성하고 예제를 추가할 수 있는 다양한 방법을 설명합니다. 워크플로에 따라 예제를 수동으로 선별하거나, 추적에서 자동으로 캡처하거나, 파일을 가져오거나, 합성 데이터를 생성할 수도 있습니다:- 추적 프로젝트에서 수동으로 추가
- 추적 프로젝트에서 자동으로 추가
- Annotation Queue의 예제에서 추가
- Prompt Playground에서 추가
- CSV 또는 JSONL 파일에서 데이터셋 가져오기
- 데이터셋 페이지에서 새 데이터셋 생성
- 데이터셋 UI를 통해 LLM으로 생성된 합성 예제 추가
추적 프로젝트에서 수동으로 추가
데이터셋을 구성하는 일반적인 패턴은 애플리케이션의 주목할 만한 추적을 데이터셋 예제로 변환하는 것입니다. 이 접근 방식을 사용하려면 LangSmith에 대한 추적을 구성해야 합니다.데이터셋을 구축하는 기법은 사용자 피드백이 좋지 않았던 추적과 같이 가장 흥미로운 추적을 필터링하여 데이터셋에 추가하는 것입니다. 추적 필터링 방법에 대한 팁은 추적 필터링 가이드를 참조하세요.
-
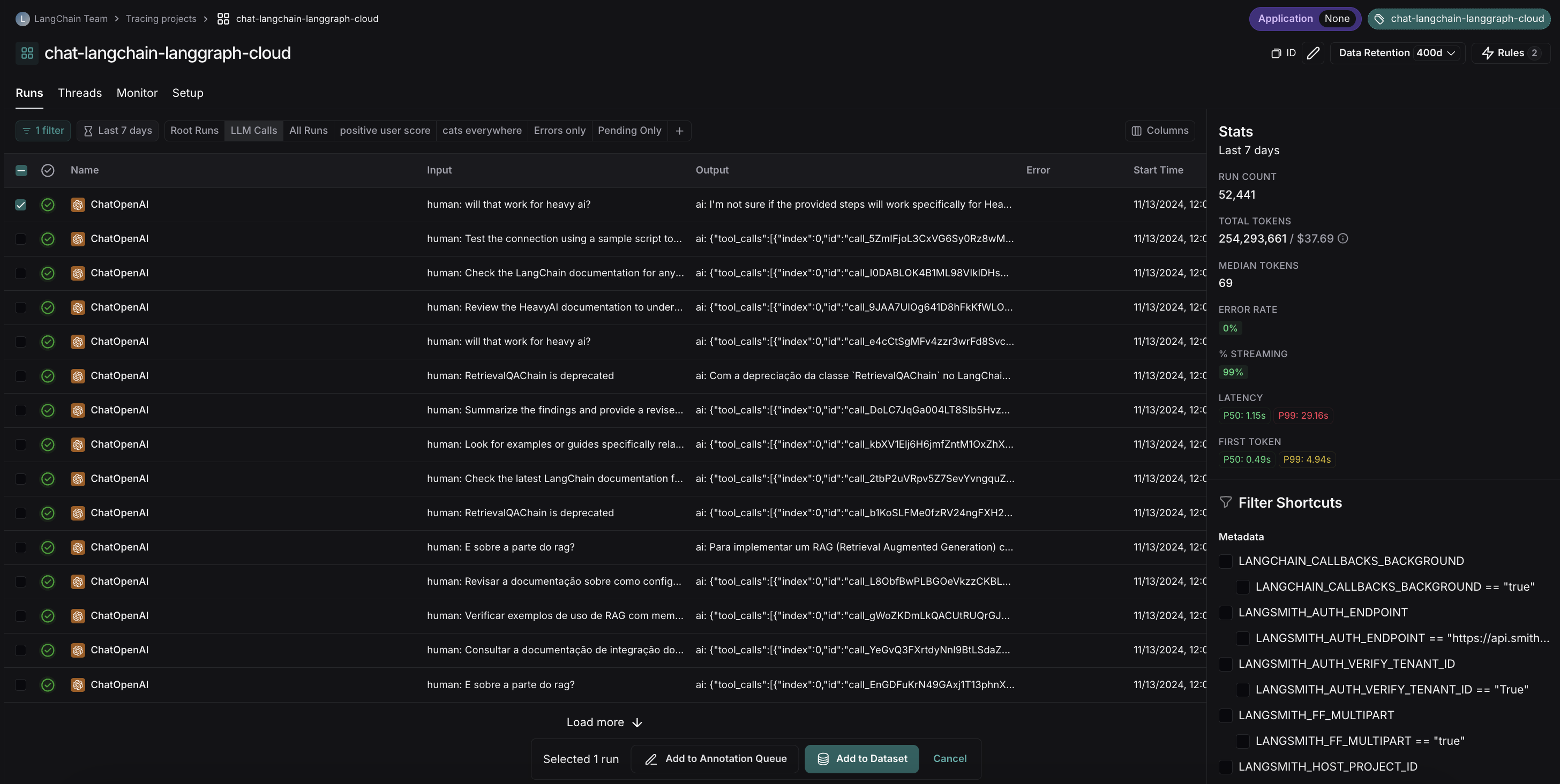
실행 테이블에서 여러 실행을 선택합니다. Runs 탭에서 여러 실행을 선택하세요. 페이지 하단에서 Add to Dataset을 클릭합니다.
-
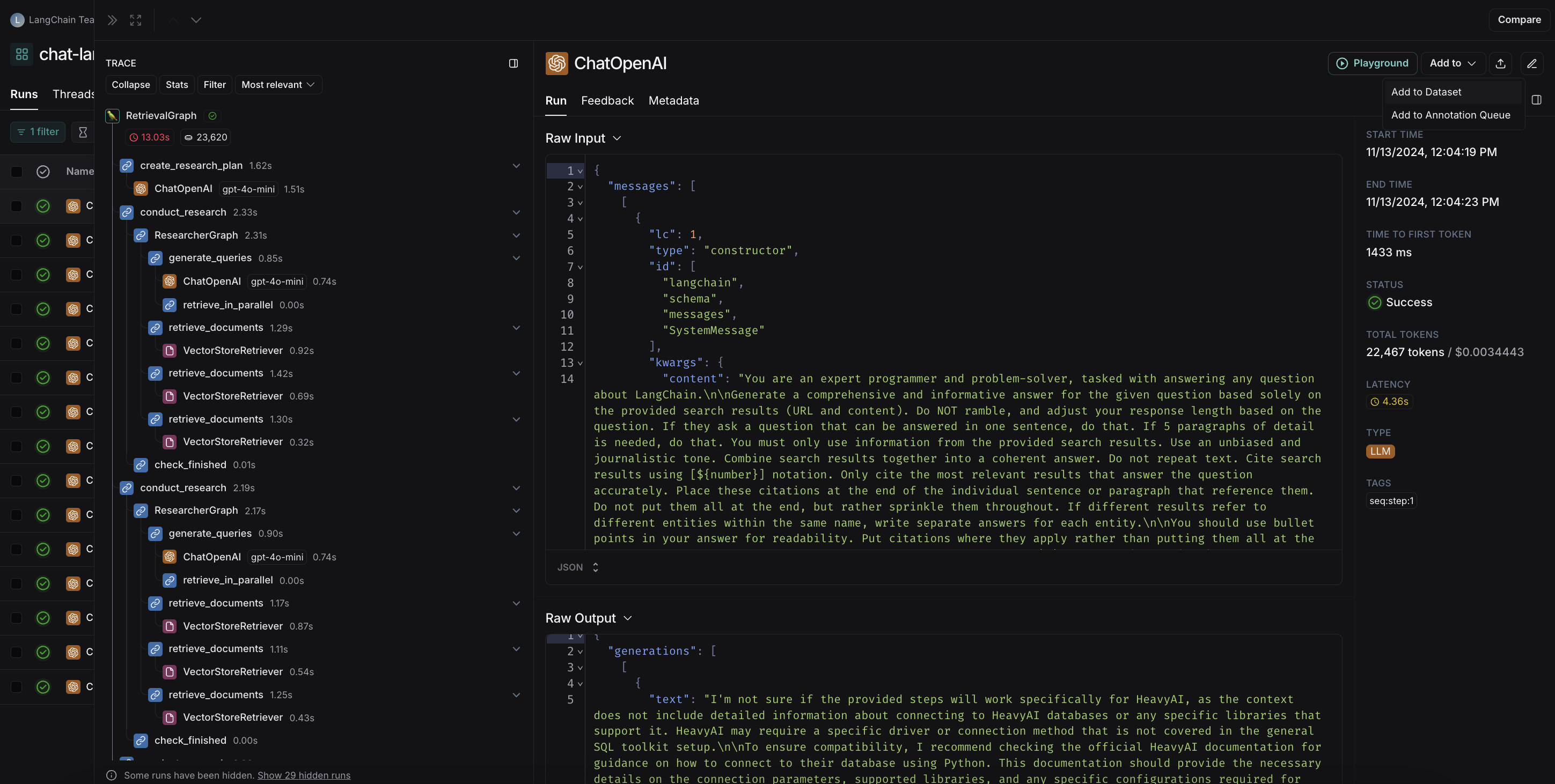
Runs 탭에서 테이블의 실행을 선택합니다. 개별 실행 세부정보 페이지에서 오른쪽 상단의 Add to -> Dataset을 선택합니다.
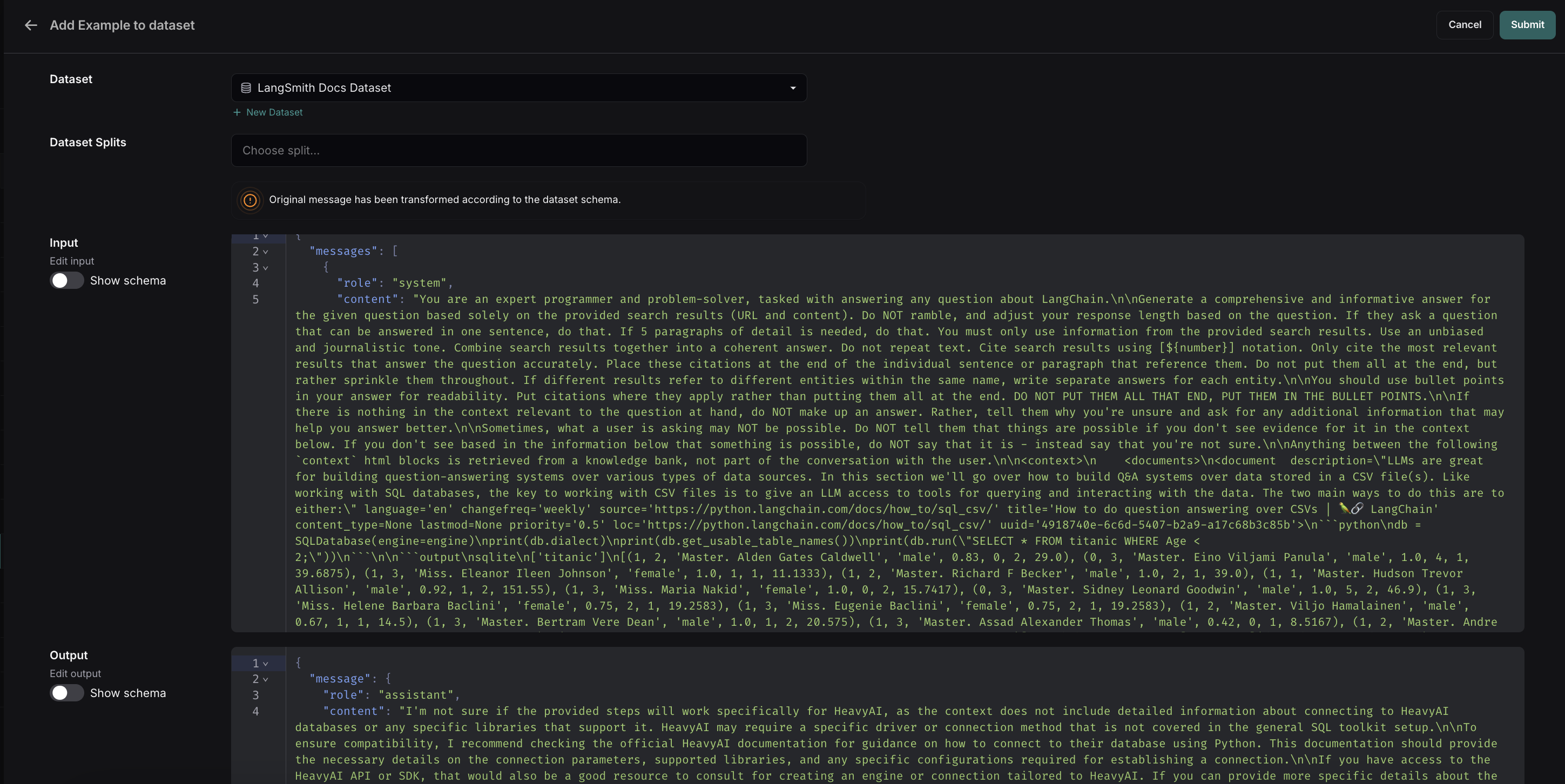
추적 프로젝트에서 자동으로 추가
실행 규칙을 사용하여 특정 조건에 따라 추적을 데이터셋에 자동으로 추가할 수 있습니다. 예를 들어, 특정 사용 사례로 태그가 지정되었거나 낮은 피드백 점수를 받은 모든 추적을 추가할 수 있습니다.Annotation Queue의 예제에서 추가
의미 있는 데이터셋을 구축하기 위해 주제 전문가에게 의존하는 경우, annotation queues를 사용하여 검토자에게 간소화된 보기를 제공하세요. 사람 검토자는 데이터셋에 추가되기 전에 추적의 입력/출력/참조 출력을 선택적으로 수정할 수 있습니다.
D를 눌러 실행을 추가하세요.
annotation queue에서 실행에 대해 수정한 내용은 데이터셋으로 이월되며, 실행과 관련된 모든 메타데이터도 복사됩니다.
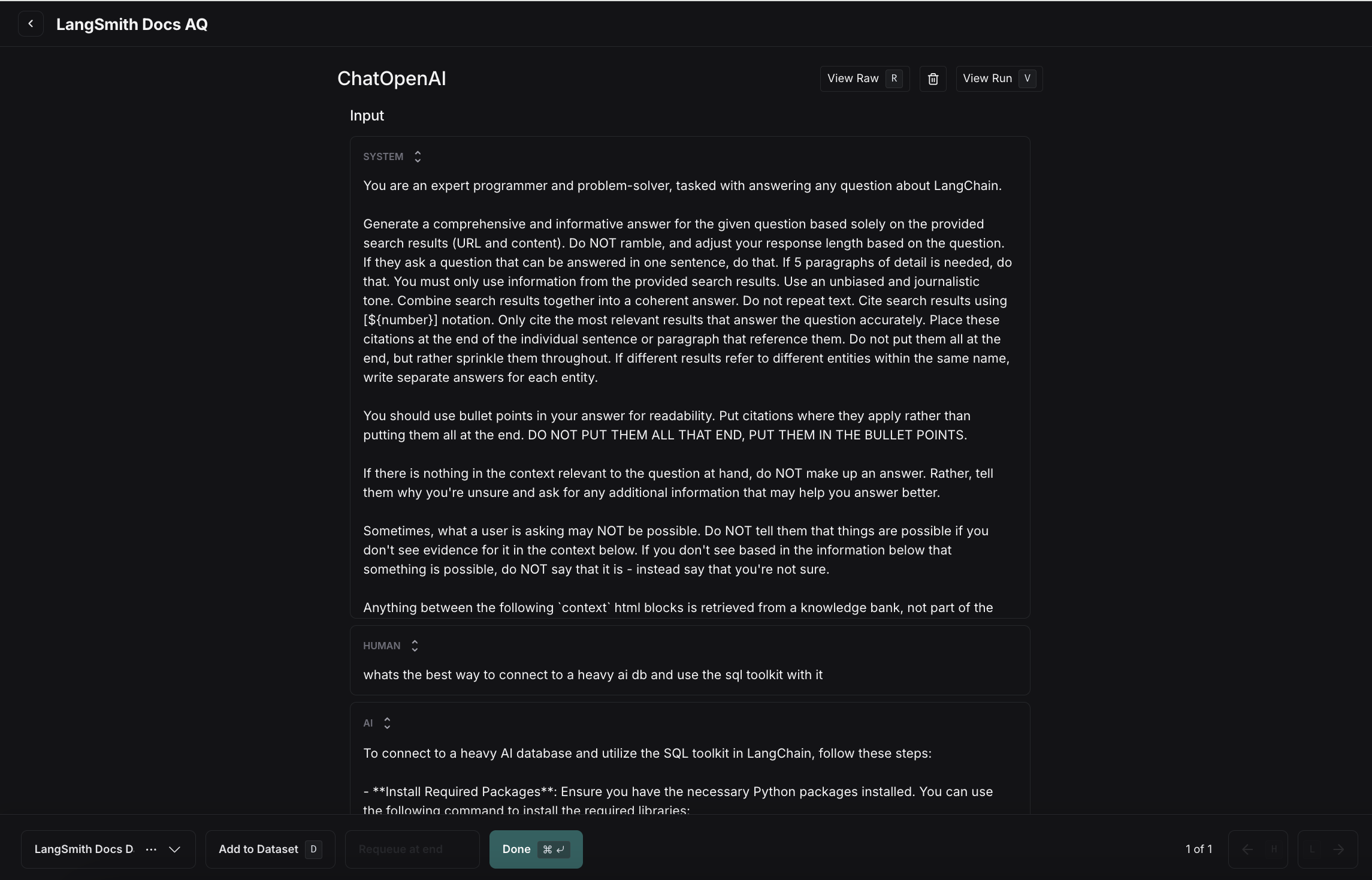
Prompt Playground에서 추가
Prompt Playground 페이지에서 Set up Evaluation을 선택하고, 새 데이터셋을 시작하는 경우 +New를 클릭하거나 기존 데이터셋에서 선택합니다.중첩된 키가 있는 데이터셋의 경우 playground에서 인라인으로 데이터셋을 생성할 수 없습니다. 중첩된 키가 있는 예제를 추가/편집하려면 데이터셋 페이지에서 편집해야 합니다.
- +Row를 사용하여 데이터셋에 새 예제 추가
- 테이블 오른쪽의 ⋮ 드롭다운을 사용하여 예제 삭제
- 참조 없는 데이터셋을 생성하는 경우 열의 x 버튼을 사용하여 “Reference Output” 열을 제거합니다. 참고: 이 작업은 되돌릴 수 없습니다.
CSV 또는 JSONL 파일에서 데이터셋 가져오기
Datasets & Experiments 페이지에서 +New Dataset을 클릭한 다음 CSV 또는 JSONL 파일에서 기존 데이터셋을 Import합니다.Datasets & Experiments 페이지에서 새 데이터셋 생성
- 왼쪽 메뉴에서 Datasets & Experiments 페이지로 이동합니다.
- + New Dataset을 클릭합니다.
- New Dataset 페이지에서 Create from scratch 탭을 선택합니다.
- 데이터셋의 이름과 설명을 추가합니다.
- (선택 사항) 데이터셋의 유효성을 검사하기 위한 데이터셋 스키마를 생성합니다.
- Create를 클릭하면 빈 데이터셋이 생성됩니다.
- 인라인으로 예제를 추가하려면 데이터셋 페이지의 Examples 탭으로 이동하세요. + Example을 클릭합니다.
- JSON으로 예제를 정의하고 Submit을 클릭합니다. 데이터셋 분할에 대한 자세한 내용은 데이터셋 분할 생성 및 관리를 참조하세요.
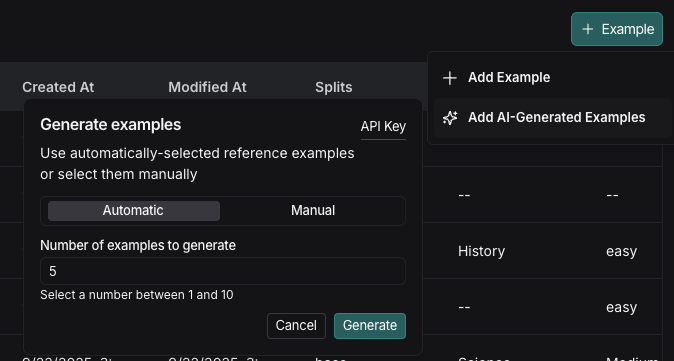
LLM으로 생성된 합성 예제 추가
데이터셋에 기존 예제와 스키마가 정의되어 있는 경우, + Example을 클릭하면 Add AI-Generated Examples 옵션이 표시됩니다. 이는 LLM을 사용하여 합성 예제를 생성합니다. Generate examples에서 다음을 수행하세요:- 창의 오른쪽 상단에 있는 API Key를 클릭하여 OpenAI API 키를 작업 공간 시크릿으로 설정합니다. 작업 공간에 이미 OpenAI API 키가 설정되어 있으면 이 단계를 건너뛸 수 있습니다.
- 를 선택합니다: Automatic 또는 Manual 참조 예제를 토글합니다. 데이터셋에서 이러한 예제를 수동으로 선택하거나 자동 선택 옵션을 사용할 수 있습니다.
- 생성하려는 합성 예제의 수를 입력합니다.
-
Generate를 클릭합니다.
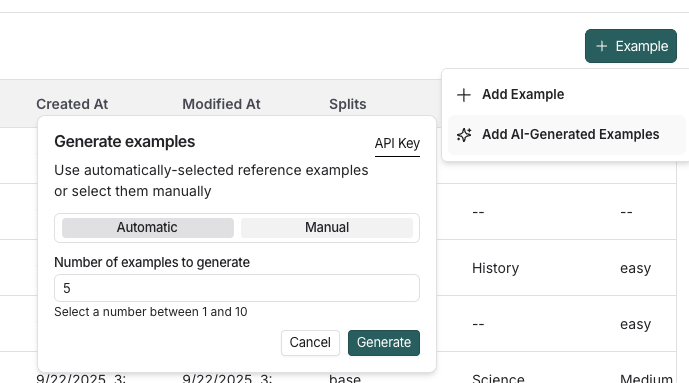
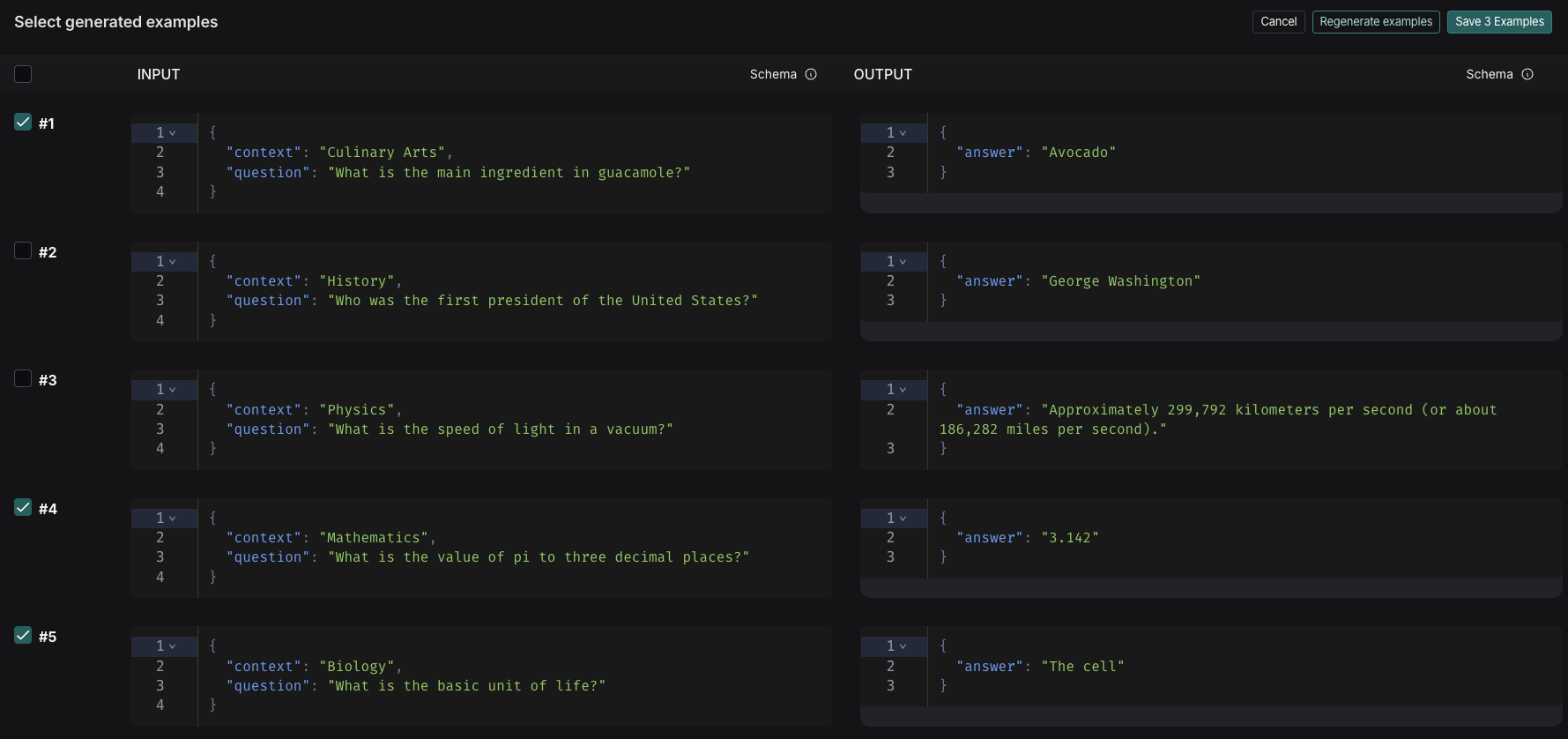
- 예제가 Select generated examples 페이지에 표시됩니다. 데이터셋에 추가할 예제를 선택하고, 최종 확인 전에 편집할 수 있는 옵션이 있습니다. Save Examples를 클릭합니다.
-
각 예제는 지정된 데이터셋 스키마에 대해 유효성이 검사되고 소스 메타데이터에 synthetic으로 태그가 지정됩니다.

데이터셋 관리
데이터셋 스키마 생성
LangSmith 데이터셋은 임의의 JSON 객체를 저장합니다. 데이터셋이 특정 JSON 스키마를 준수하도록 스키마를 정의하는 것을 권장하지만 필수는 아닙니다. 데이터셋 스키마는 표준 JSON schema로 정의되며, 메시지 및 도구와 같은 일반적인 기본 타입을 더 쉽게 지정할 수 있도록 몇 가지 사전 빌드된 타입이 추가되었습니다. 스키마의 특정 필드에는+ Transformations 옵션이 있습니다. 변환은 활성화된 경우 데이터셋에 예제를 추가할 때 예제를 업데이트하는 전처리 단계입니다. 예를 들어 convert to OpenAI messages 변환은 LangChain 메시지와 같은 메시지 유사 객체를 OpenAI 메시지 형식으로 변환합니다.
사용 가능한 변환의 전체 목록은 참조 문서를 참조하세요.
LangChain ChatModels의 프로덕션 추적이나 LangSmith OpenAI wrapper를 사용한 OpenAI 호출을 데이터셋에 수집하려는 경우, 메시지와 도구를 테스트를 위해 모든 모델에서 사용할 수 있는 업계 표준 OpenAI 형식으로 변환하는 사전 빌드된 Chat Model 스키마를 제공합니다. 또한 사용 사례에 맞게 템플릿 설정을 사용자 지정할 수도 있습니다.자세한 내용은 데이터셋 변환 참조를 참조하세요.
데이터셋 분할 생성 및 관리
데이터셋 분할은 데이터를 세그먼트화하는 데 사용할 수 있는 데이터셋의 분할입니다. 예를 들어, 머신러닝 워크플로에서는 데이터셋을 훈련, 검증, 테스트 세트로 분할하는 것이 일반적입니다. 이는 모델이 훈련 데이터에서는 잘 수행되지만 보지 못한 데이터에서는 잘 수행되지 않는 과적합을 방지하는 데 유용할 수 있습니다. 평가 워크플로에서는 별도로 평가하려는 여러 범주가 있는 데이터셋이 있는 경우 이 작업을 수행하는 것이 유용할 수 있습니다. 또는 향후 데이터셋에 포함하고 싶지만 지금은 별도로 유지하려는 새로운 사용 사례를 테스트하는 경우에도 유용합니다. 메타데이터를 통해 수동으로 동일한 효과를 얻을 수 있지만, 분할은 평가를 위해 데이터셋을 별도의 그룹으로 분할하는 상위 수준의 조직에 사용될 것으로 예상하는 반면, 메타데이터는 태그 및 출처에 대한 정보와 같이 예제에 대한 정보를 저장하는 데 더 많이 사용될 것입니다. 머신러닝에서는 분할을 별도로 유지하는 것이 모범 사례입니다(각 예제는 정확히 하나의 분할에 속함). 그러나 LangSmith에서는 동일한 예제에 대해 여러 분할을 선택할 수 있도록 허용합니다. 일부 평가 워크플로에서는 이것이 의미가 있을 수 있기 때문입니다. 예를 들어 애플리케이션을 평가하려는 여러 범주에 해당하는 예제가 있는 경우입니다. 앱에서 분할을 생성하고 관리하려면 데이터셋에서 일부 예제를 선택하고 “Add to Split”을 클릭할 수 있습니다. 표시되는 팝업 메뉴에서 선택한 예제에 대한 분할을 선택 및 선택 취소하거나 새 분할을 생성할 수 있습니다.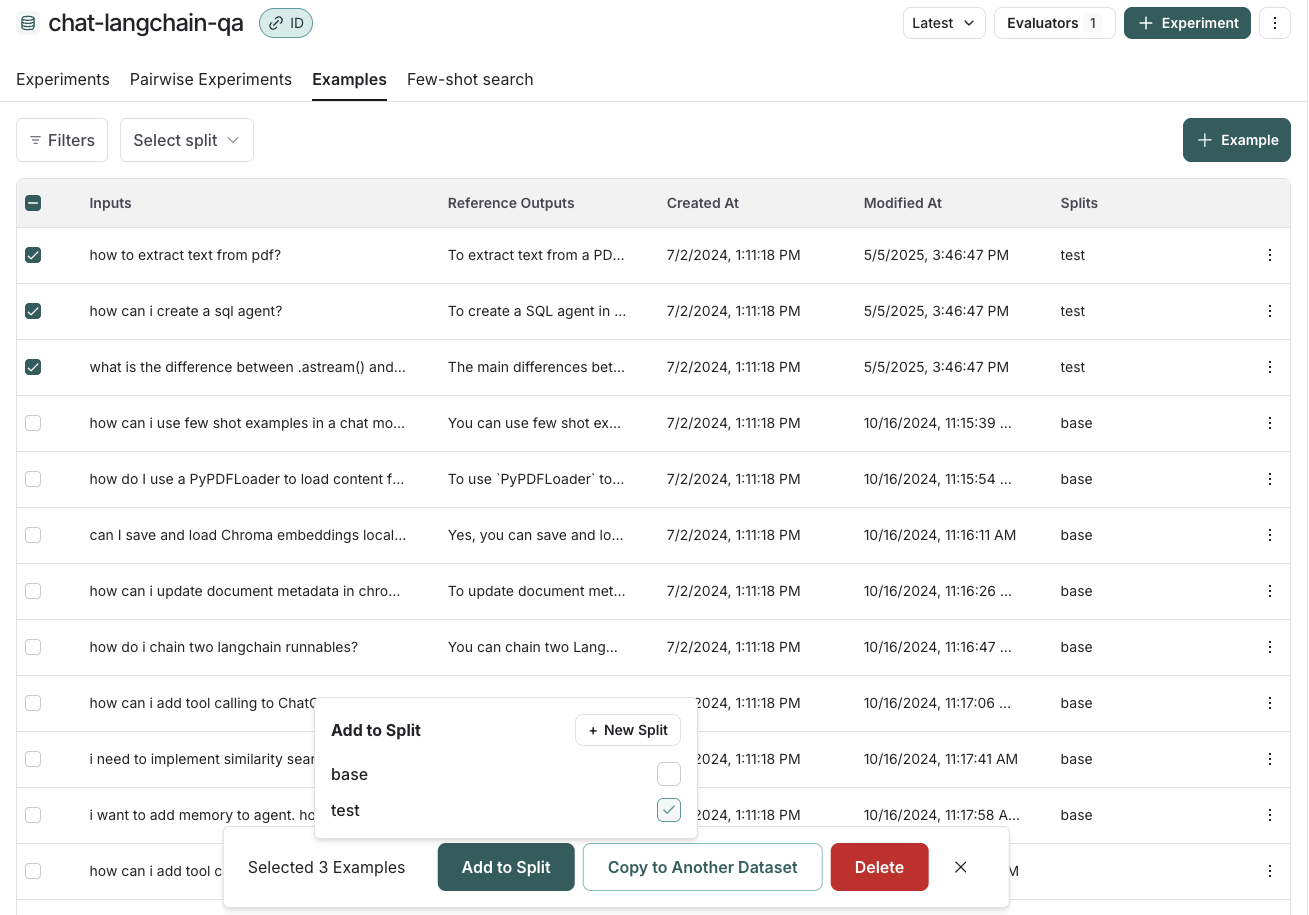
예제 메타데이터 편집
예제를 클릭한 다음 팝오버의 오른쪽 상단에 있는 “Edit”를 클릭하여 예제에 메타데이터를 추가할 수 있습니다. 이 페이지에서 기존 메타데이터를 업데이트/삭제하거나 새 메타데이터를 추가할 수 있습니다. 이를 사용하여 예제에 대한 태그 또는 버전 정보와 같은 정보를 저장할 수 있으며, 실험 결과를 분석할 때 그룹화하거나 SDK에서list_examples를 호출할 때 필터링할 수 있습니다.
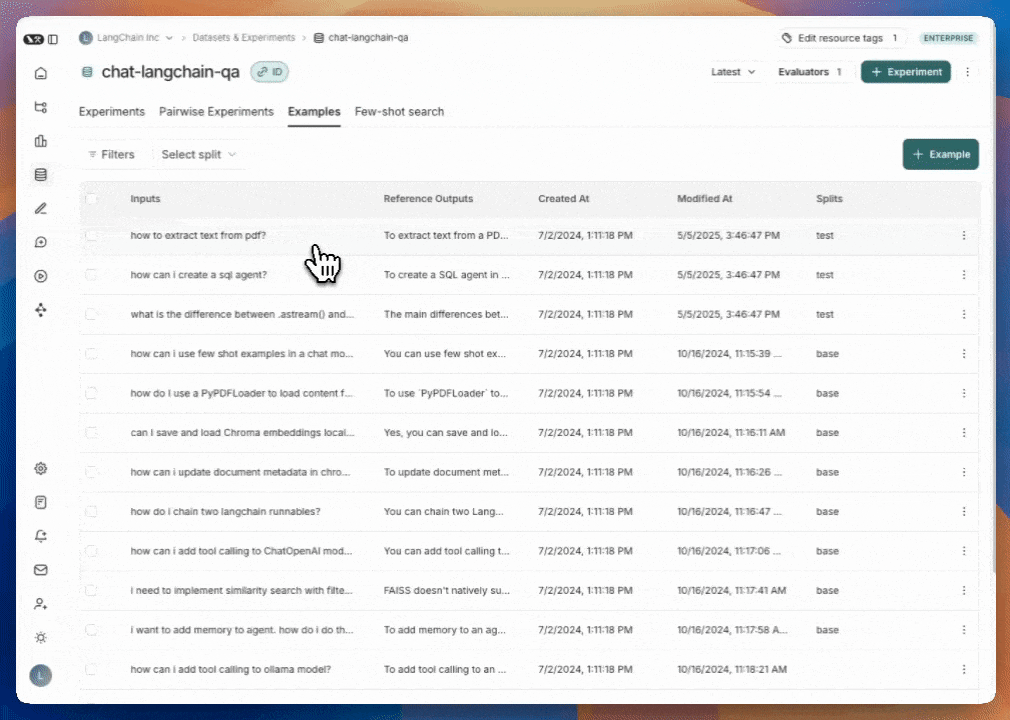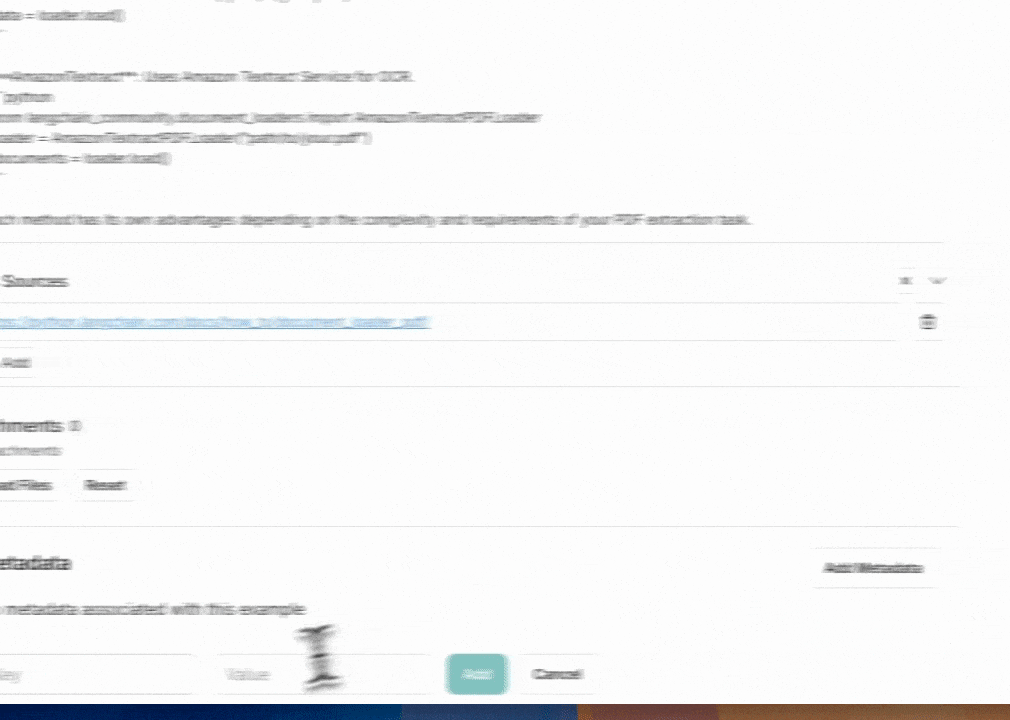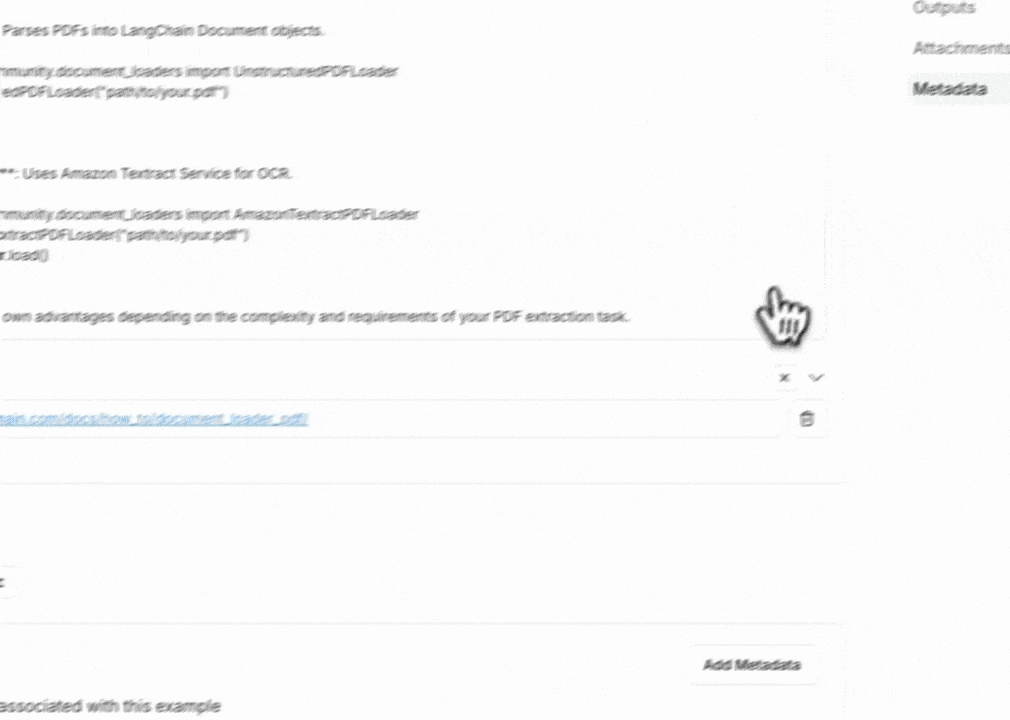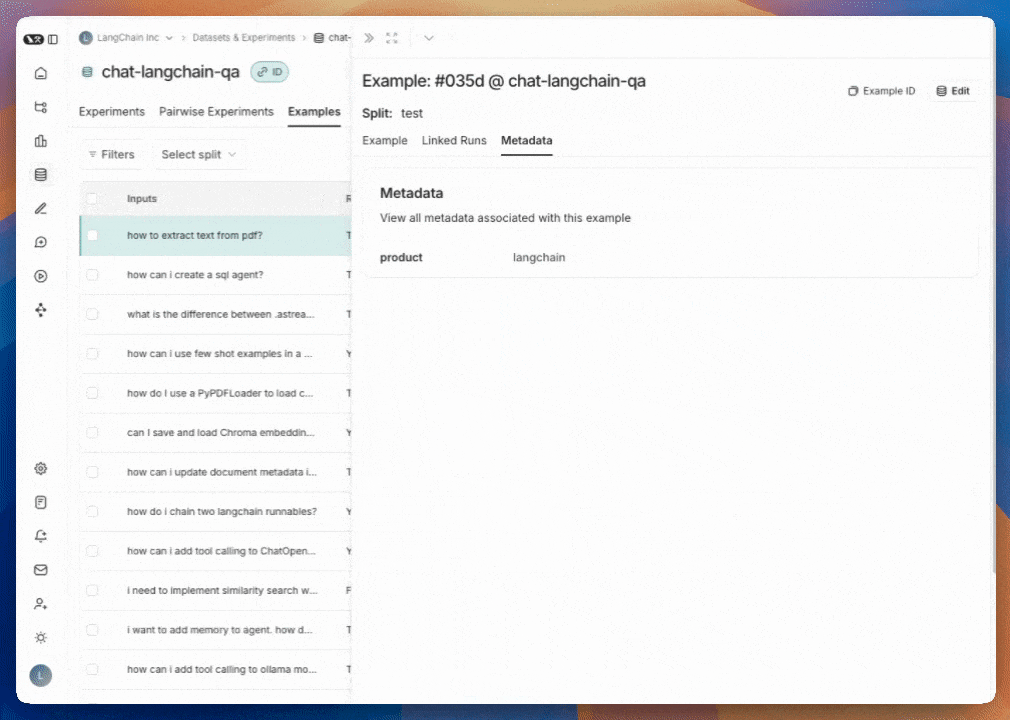
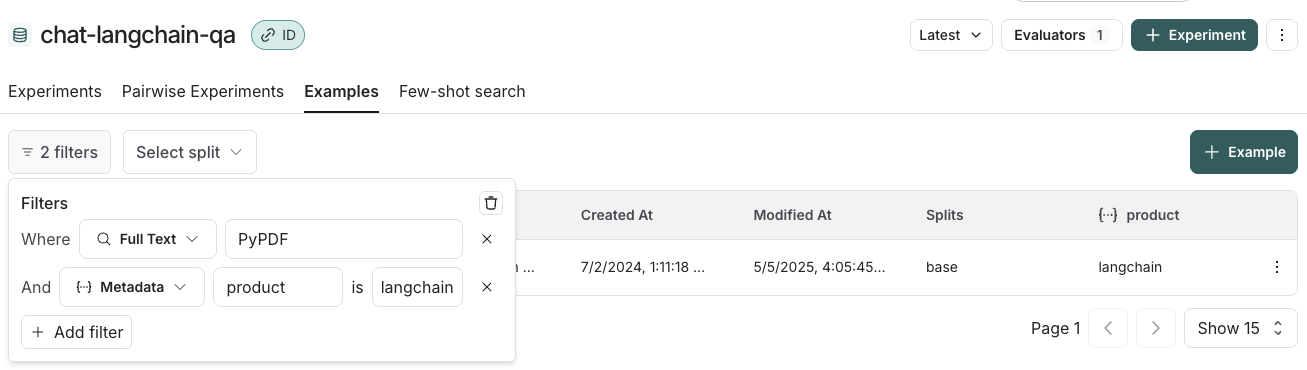
예제 필터링
분할, 메타데이터 키/값으로 예제를 필터링하거나 예제에 대한 전체 텍스트 검색을 수행할 수 있습니다. 이러한 필터링 옵션은 예제 테이블의 왼쪽 상단에서 사용할 수 있습니다.- 분할로 필터링: Select split > 필터링할 분할 선택
- 메타데이터로 필터링: Filters > 드롭다운에서 “Metadata” 선택 > 필터링할 메타데이터 키 및 값 선택
- 전체 텍스트 검색: Filters > 드롭다운에서 “Full Text” 선택 > 검색 기준 입력