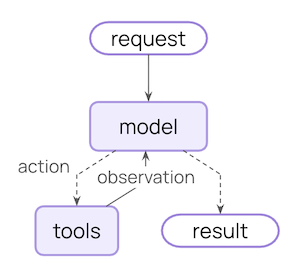
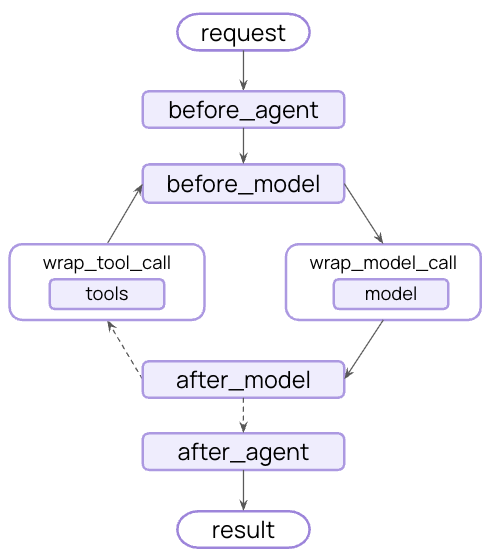
import { createAgent, modelFallbackMiddleware } from "langchain";const agent = createAgent({ model: "openai:gpt-4o", // 기본 모델 tools: [...], middleware: [ modelFallbackMiddleware( "openai:gpt-4o-mini", // 오류 시 첫 번째 시도 "anthropic:claude-3-5-sonnet-20241022" // 그 다음 이것 ), ],});
이 미들웨어는 에이전트에게 write_todos 도구와 효과적인 작업 계획을 안내하는 시스템 프롬프트를 자동으로 제공합니다.
Copy
import { createAgent, HumanMessage, todoListMiddleware } from "langchain";const agent = createAgent({ model: "openai:gpt-4o", tools: [ /* ... */ ], middleware: [todoListMiddleware()] as const,});const result = await agent.invoke({ messages: [new HumanMessage("Help me refactor my codebase")],});console.log(result.todos); // 상태 추적이 있는 할 일 항목 배열
import { createAgent, llmToolSelectorMiddleware } from "langchain";const agent = createAgent({ model: "openai:gpt-4o", tools: [tool1, tool2, tool3, tool4, tool5, ...], // 많은 도구 middleware: [ llmToolSelectorMiddleware({ model: "openai:gpt-4o-mini", // 선택에 더 저렴한 모델 사용 maxTools: 3, // 가장 관련성 높은 도구 3개로 제한 alwaysInclude: ["search"], // 특정 도구 항상 포함 }), ],});
미들웨어는 사용자 정의 속성으로 에이전트의 상태를 확장할 수 있습니다. 사용자 정의 상태 타입을 정의하고 state_schema로 설정합니다:
Copy
import { createMiddleware, createAgent, HumanMessage } from "langchain";import * as z from "zod";// 사용자 정의 상태 요구 사항이 있는 미들웨어const callCounterMiddleware = createMiddleware({ name: "CallCounterMiddleware", stateSchema: z.object({ modelCallCount: z.number().default(0), userId: z.string().optional(), }), beforeModel: (state) => { // 사용자 정의 상태 속성 접근 if (state.modelCallCount > 10) { return { jumpTo: "end" }; } return; }, afterModel: (state) => { // 사용자 정의 상태 업데이트 return { modelCallCount: state.modelCallCount + 1 }; },});
Copy
const agent = createAgent({ model: "openai:gpt-4o", tools: [...], middleware: [callCounterMiddleware] as const,});// TypeScript가 필요한 상태 속성을 강제합니다const result = await agent.invoke({ messages: [new HumanMessage("Hello")], modelCallCount: 0, // 기본값으로 인해 선택사항 userId: "user-123", // 선택사항});
import { createAgent, createMiddleware } from "langchain";const toolSelectorMiddleware = createMiddleware({ name: "ToolSelector", wrapModelCall: (request, handler) => { // 상태/컨텍스트에 따라 작고 관련성 높은 도구 하위 집합 선택 const relevantTools = selectRelevantTools(request.state, request.runtime); const modifiedRequest = { ...request, tools: relevantTools }; return handler(modifiedRequest); },});const agent = createAgent({ model: "openai:gpt-4o", tools: allTools, // 사용 가능한 모든 도구를 미리 등록해야 함 // 미들웨어를 사용하여 주어진 실행에 관련된 더 작은 하위 집합을 선택할 수 있습니다. middleware: [toolSelectorMiddleware],});
Show 확장 예제: GitHub vs GitLab 도구 선택
Copy
import * as z from "zod";import { createAgent, createMiddleware, tool, HumanMessage } from "langchain";const githubCreateIssue = tool( async ({ repo, title }) => ({ url: `https://github.com/${repo}/issues/1`, title, }), { name: "github_create_issue", description: "Create an issue in a GitHub repository", schema: z.object({ repo: z.string(), title: z.string() }), });const gitlabCreateIssue = tool( async ({ project, title }) => ({ url: `https://gitlab.com/${project}/-/issues/1`, title, }), { name: "gitlab_create_issue", description: "Create an issue in a GitLab project", schema: z.object({ project: z.string(), title: z.string() }), });const allTools = [githubCreateIssue, gitlabCreateIssue];const toolSelector = createMiddleware({ name: "toolSelector", contextSchema: z.object({ provider: z.enum(["github", "gitlab"]) }), wrapModelCall: (request, handler) => { const provider = request.runtime.context.provider; const toolName = provider === "gitlab" ? "gitlab_create_issue" : "github_create_issue"; const selectedTools = request.tools.filter((t) => t.name === toolName); const modifiedRequest = { ...request, tools: selectedTools }; return handler(modifiedRequest); },});const agent = createAgent({ model: "openai:gpt-4o", tools: allTools, middleware: [toolSelector],});// GitHub 컨텍스트로 호출await agent.invoke( { messages: [ new HumanMessage("Open an issue titled 'Bug: where are the cats' in the repository `its-a-cats-game`"), ], }, { context: { provider: "github" }, });