

개요
이 튜토리얼에서는 LangGraph를 사용하여 검색 에이전트를 구축합니다. LangChain은 LangGraph 프리미티브를 사용하여 구현된 내장 에이전트 구현을 제공합니다. 더 깊은 수준의 커스터마이징이 필요한 경우, 에이전트를 LangGraph에서 직접 구현할 수 있습니다. 이 가이드는 검색 에이전트의 예제 구현을 보여줍니다. 검색 에이전트는 LLM이 벡터스토어에서 컨텍스트를 검색할지 또는 사용자에게 직접 응답할지에 대한 결정을 내리도록 하고 싶을 때 유용합니다. 튜토리얼을 마치면 다음을 수행하게 됩니다:- 검색에 사용할 문서를 가져오고 전처리합니다.
- 해당 문서를 시맨틱 검색을 위해 인덱싱하고 에이전트를 위한 리트리버 도구를 생성합니다.
- 리트리버 도구를 언제 사용할지 결정할 수 있는 에이전틱 RAG 시스템을 구축합니다.
개념
다음 개념을 다룹니다:설정
필요한 패키지를 다운로드하고 API 키를 설정하겠습니다:1. 문서 전처리
- RAG 시스템에서 사용할 문서를 가져옵니다. Lilian Weng의 훌륭한 블로그에서 가장 최근의 세 페이지를 사용하겠습니다. 먼저
CheerioWebBaseLoader를 사용하여 페이지의 콘텐츠를 가져옵니다:
- 가져온 문서를 벡터스토어에 인덱싱하기 위해 더 작은 청크로 분할합니다:
2. 리트리버 도구 생성
이제 분할된 문서가 있으므로, 시맨틱 검색에 사용할 벡터 스토어에 인덱싱할 수 있습니다.- 인메모리 벡터 스토어와 OpenAI 임베딩을 사용합니다:
- LangChain의 사전 구축된
createRetrieverTool을 사용하여 리트리버 도구를 생성합니다:
3. 쿼리 생성
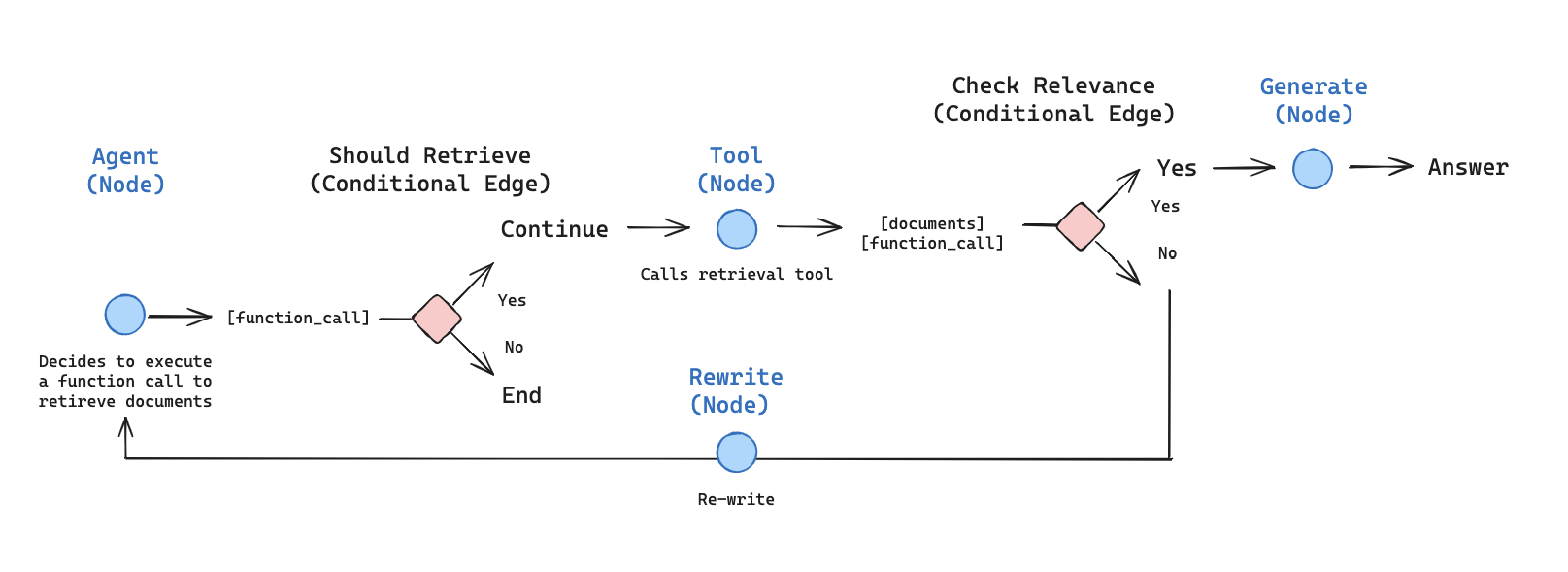
이제 에이전틱 RAG 그래프를 위한 컴포넌트(노드와 엣지)를 구축하기 시작하겠습니다.generateQueryOrRespond노드를 구축합니다. 이 노드는 현재 그래프 상태(메시지 목록)를 기반으로 응답을 생성하기 위해 LLM을 호출합니다. 입력 메시지가 주어지면, 리트리버 도구를 사용하여 검색할지 또는 사용자에게 직접 응답할지 결정합니다..bindTools를 통해 앞서 생성한tools에 대한 액세스 권한을 채팅 모델에 제공하고 있다는 점에 주목하세요:
- 임의의 입력으로 시도해봅니다:
- 시맨틱 검색이 필요한 질문을 합니다:
4. 문서 등급 평가
- 검색된 문서가 질문과 관련이 있는지 판단하기 위해 노드 —
gradeDocuments를 추가합니다. 문서 등급 평가를 위해 Zod를 사용한 구조화된 출력을 가진 모델을 사용합니다. 또한 등급 평가 결과를 확인하고 이동할 노드의 이름을 반환하는 조건부 엣지 —checkRelevance를 추가합니다(generate또는rewrite):
- 도구 응답에 관련 없는 문서를 포함하여 실행합니다:
- 관련 문서가 그렇게 분류되는지 확인합니다:
5. 질문 재작성
rewrite노드를 구축합니다. 리트리버 도구는 잠재적으로 관련 없는 문서를 반환할 수 있으며, 이는 원래 사용자 질문을 개선할 필요가 있음을 나타냅니다. 이를 위해rewrite노드를 호출합니다:
- 시도해봅니다:
6. 답변 생성
generate노드를 구축합니다: 등급 평가 검사를 통과하면, 원래 질문과 검색된 컨텍스트를 기반으로 최종 답변을 생성할 수 있습니다:
- 시도해봅니다:
7. 그래프 조립
이제 모든 노드와 엣지를 완전한 그래프로 조립하겠습니다:generateQueryOrRespond로 시작하고 리트리버 도구를 호출해야 하는지 판단합니다- 조건부 엣지를 사용하여 다음 단계로 라우팅합니다:
generateQueryOrRespond가tool_calls를 반환한 경우, 리트리버 도구를 호출하여 컨텍스트를 검색합니다- 그렇지 않으면, 사용자에게 직접 응답합니다
- 질문에 대한 검색된 문서 콘텐츠의 관련성을 등급 평가하고(
gradeDocuments) 다음 단계로 라우팅합니다:- 관련이 없으면,
rewrite를 사용하여 질문을 재작성한 다음generateQueryOrRespond를 다시 호출합니다 - 관련이 있으면,
generate로 진행하고 검색된 문서 컨텍스트를 가진 @[ToolMessage]를 사용하여 최종 응답을 생성합니다
- 관련이 없으면,