

- LLM-as-a-judge: LLM을 사용하여 트레이스를 평가하는 방식으로, 사람과 유사한 판단을 확장 가능하게 대체합니다(예: 유해성, 환각, 정확성). 두 가지 수준의 세분성을 지원합니다:
- 실행 수준: 단일 실행을 평가합니다.
- 스레드 수준: 스레드 내의 모든 트레이스를 평가합니다.
- 사용자 정의 코드: LangSmith에서 직접 Python으로 평가자를 작성합니다. 주로 데이터의 구조나 통계적 속성을 검증하는 데 사용됩니다.
온라인 평가자가 트레이스 내의 어떤 실행에서든 실행되면, 해당 트레이스는 자동으로 확장 데이터 보존으로 업그레이드됩니다. 이 업그레이드는 트레이스 요금에 영향을 미치지만, 평가 기준을 충족하는 트레이스(일반적으로 분석에 가장 가치 있는 트레이스)가 조사를 위해 보존되도록 보장합니다.
온라인 평가자 보기
Tracing Projects 탭으로 이동하여 트레이싱 프로젝트를 선택합니다. 해당 프로젝트의 기존 온라인 평가자를 보려면 Evaluators 탭을 클릭하세요.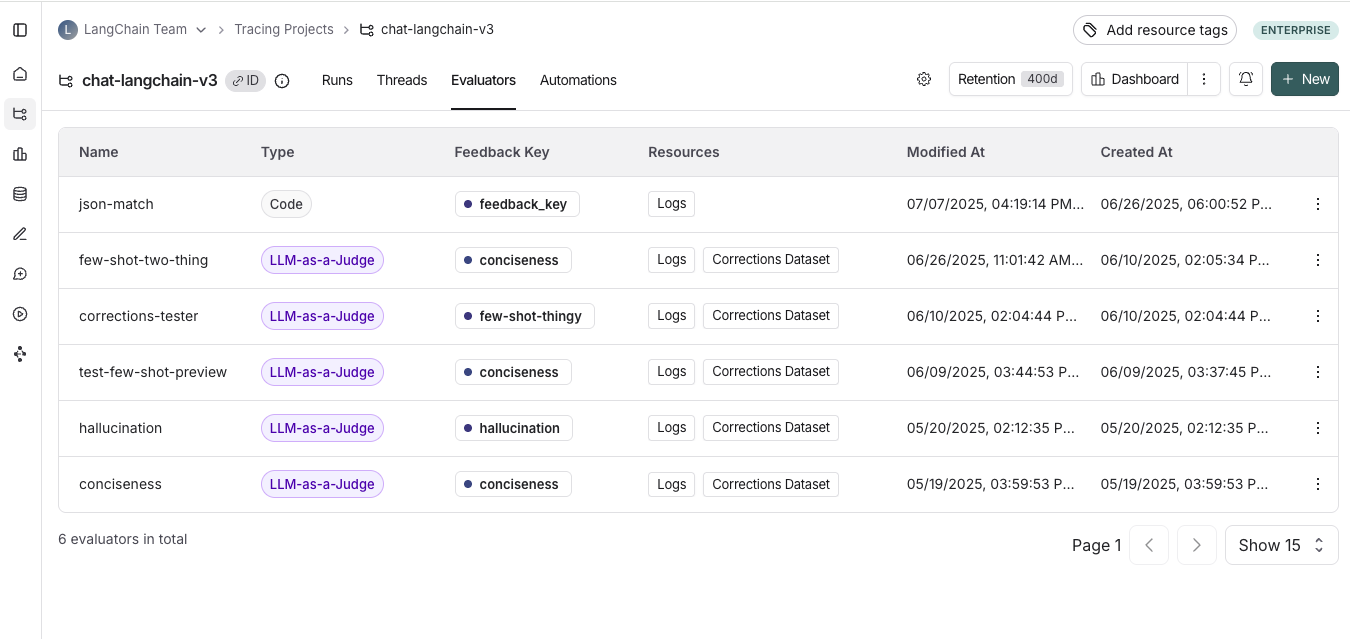
온라인 평가자 구성
1. 온라인 평가자로 이동
Tracing Projects 탭으로 이동하여 트레이싱 프로젝트를 선택합니다. 트레이싱 프로젝트 페이지의 오른쪽 상단에 있는 + New를 클릭한 다음 New Evaluator를 클릭합니다. 구성하려는 평가자를 선택하세요.2. 평가자 이름 지정
3. 필터 생성
예를 들어, 다음과 같은 경우에 특정 평가자를 적용할 수 있습니다:- 사용자가 피드백을 남긴 실행 중 응답이 만족스럽지 않다고 표시한 경우
- 특정 도구 호출을 실행한 실행. 자세한 내용은 도구 호출 필터링을 참조하세요.
- 특정 메타데이터와 일치하는 실행(예:
plan_type으로 트레이스를 기록하고 엔터프라이즈 고객의 트레이스에만 평가를 실행하려는 경우). 자세한 내용은 트레이스에 메타데이터 추가를 참조하세요.
4. (선택 사항) 샘플링 비율 구성
샘플링 비율을 구성하여 자동화 작업을 트리거하는 필터링된 실행의 비율을 제어합니다. 예를 들어, 비용을 제어하기 위해 평가자를 트레이스의 10%에만 적용하도록 필터를 설정할 수 있습니다. 이렇게 하려면 샘플링 비율을 0.1로 설정하면 됩니다.5. (선택 사항) 과거 실행에 규칙 적용
Apply to past runs를 토글하고 “Backfill from” 날짜를 입력하여 과거 실행에 규칙을 적용합니다. 이는 규칙 생성 시에만 가능합니다. 참고: 백필은 백그라운드 작업으로 처리되므로 결과가 즉시 표시되지 않습니다. 백필 진행 상황을 추적하려면 트레이싱 프로젝트 내의 Evaluators 탭으로 이동하여 생성한 평가자의 로그 버튼을 클릭하여 평가자의 로그를 확인할 수 있습니다. 온라인 평가자 로그는 자동화 규칙 로그와 유사합니다.- 평가자 이름 추가
- 선택적으로 평가자를 적용할 실행을 필터링하거나 샘플링 비율을 구성합니다.
- Apply Evaluator를 선택합니다
6. 평가자 유형 선택
LLM-as-a-judge 온라인 평가자 구성
LLM-as-a-judge 평가자를 구성하려면 이 가이드를 참조하세요.사용자 정의 코드 평가자 구성
custom code 평가자를 선택합니다.평가 함수 작성
사용자 정의 코드 평가자 제한 사항허용된 라이브러리: 모든 표준 라이브러리 함수와 다음 공개 패키지를 가져올 수 있습니다:네트워크 액세스: 사용자 정의 코드 평가자에서는 인터넷에 액세스할 수 없습니다.
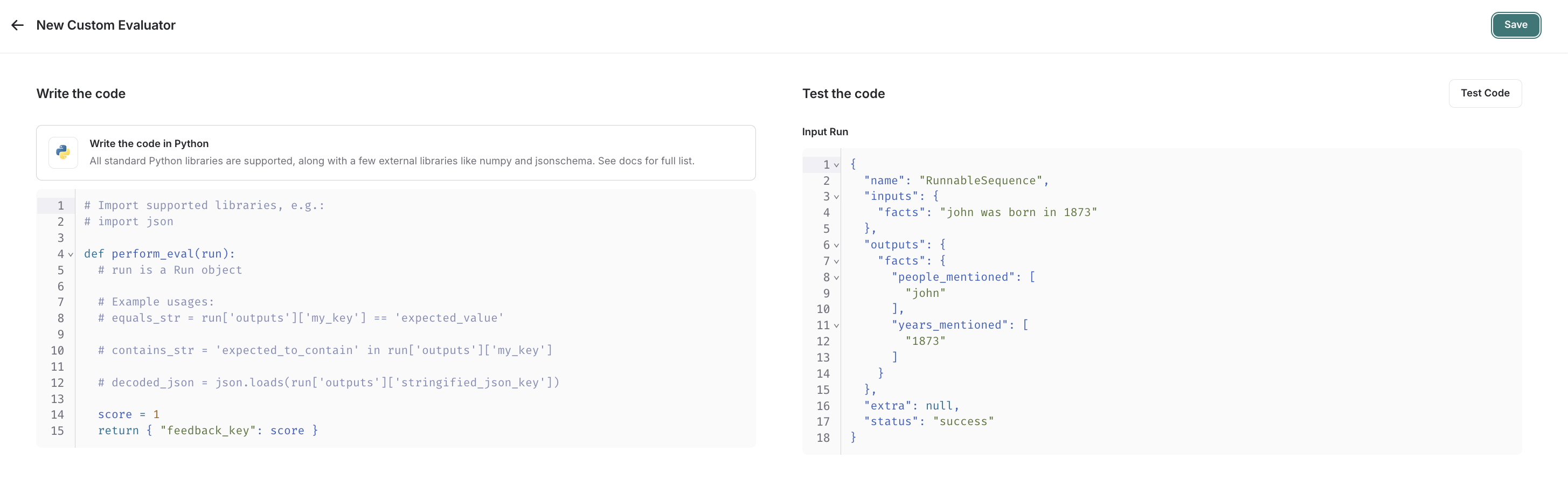
Run(참조). 평가할 샘플링된 실행을 나타냅니다.
- 피드백 딕셔너리: 키는 반환하려는 피드백 유형이고 값은 해당 피드백 키에 대해 부여할 점수입니다. 예를 들어,
{"correctness": 1, "silliness": 0}은 실행에 두 가지 유형의 피드백을 생성하며, 하나는 정확하다고 말하고 다른 하나는 우스꽝스럽지 않다고 말합니다.
평가 함수 테스트 및 저장
저장하기 전에 Test Code를 클릭하여 최근 실행에서 평가자 함수를 테스트하여 코드가 제대로 실행되는지 확인할 수 있습니다. Save를 클릭하면 온라인 평가자가 새로 샘플링된 실행(또는 백필 옵션을 선택한 경우 백필된 실행)에서 실행됩니다. 비디오 튜토리얼을 선호하신다면 Introduction to LangSmith Course의 온라인 평가 비디오를 확인하세요.비디오 가이드
다중 턴 온라인 평가자 구성
다중 턴 온라인 평가자를 사용하면 개별 교환이 아닌 사람과 에이전트 간의 전체 대화를 평가할 수 있습니다. 스레드의 모든 턴에 걸친 엔드투엔드 상호 작용 품질을 측정합니다. 다중 턴 평가를 사용하여 다음을 측정할 수 있습니다:- 의미론적 의도: 사용자가 무엇을 하려고 했는지.
- 의미론적 결과: 실제로 무슨 일이 일어났는지, 작업이 성공했는지.
- 궤적: 도구 호출의 궤적을 포함하여 대화가 어떻게 전개되었는지.
다중 턴 온라인 평가를 실행하면 스레드 내의 각 트레이스가 자동으로 확장 데이터 보존으로 업그레이드됩니다. 이 업그레이드는 트레이스 요금에 영향을 미치지만, 평가 기준을 충족하는 트레이스(일반적으로 분석에 가장 가치 있는 트레이스)가 조사를 위해 보존되도록 보장합니다.
전제 조건
- 트레이싱 프로젝트가 스레드를 사용해야 합니다.
- 스레드의 각 트레이스의 최상위 입력 및 출력에는 메시지 목록이 포함된
messages키가 있어야 합니다. LangChain, OpenAI Chat Completions, Anthropic Messages 형식의 메시지를 지원합니다.- 각 트레이스의 최상위 입력 및 출력에 대화의 최신 메시지만 포함된 경우, LangSmith는 자동으로 턴 간의 메시지를 스레드로 결합합니다.
- 각 트레이스의 최상위 입력 및 출력에 전체 대화 기록이 포함된 경우, LangSmith는 이를 직접 사용합니다.
트레이스가 위의 형식을 따르지 않으면 스레드 수준 평가자가 작동하지 않습니다. 각 트레이스의 최상위 입력 및 출력에
messages 목록이 포함되도록 LangSmith에 트레이스하는 방법을 업데이트해야 합니다.자세한 내용은 문제 해결 섹션을 참조하세요.구성
- Tracing Projects 탭으로 이동하여 트레이싱 프로젝트를 선택합니다.
- 트레이싱 프로젝트 페이지의 오른쪽 상단에 있는 + New > New Evaluator > Evaluate a multi-turn thread를 클릭합니다.
- 평가자 이름을 지정합니다.
- 필터 또는 샘플링 비율을 적용합니다.
필터 또는 샘플링을 사용하여 평가자 비용을 제어합니다. 예를 들어, N턴 미만의 스레드만 평가하거나 모든 스레드의 10%를 샘플링합니다. - 유휴 시간을 구성합니다.
스레드 수준 평가자를 처음 구성할 때 유휴 시간을 정의합니다. 유휴 시간은 스레드의 마지막 트레이스 이후 스레드가 완료된 것으로 간주되어 평가할 준비가 된 것으로 간주되기까지의 시간입니다. 이 값은 앱에서 예상되는 사용자 상호 작용 길이를 반영해야 합니다. 프로젝트의 모든 평가자에 적용됩니다.
-
모델을 구성합니다.
평가자에 사용할 공급자와 모델을 선택합니다. 스레드는 길어지는 경향이 있으므로 한계에 도달하지 않도록 더 높은 컨텍스트 윈도우를 가진 모델을 사용해야 합니다. 예를 들어, OpenAI의 GPT-4.1 mini 또는 Gemini 2.5 Flash는 둘 다 1M+ 토큰 컨텍스트 윈도우를 가지고 있어 좋은 옵션입니다. -
LLM-as-a-judge 프롬프트를 구성합니다.
평가하려는 내용을 정의합니다. 이 프롬프트는 스레드를 평가하는 데 사용됩니다. 또한messages목록의 어느 부분이 평가자에게 전달되어 수신하는 콘텐츠를 제어할지 구성할 수 있습니다:- 모든 메시지: 전체 메시지 목록을 전송합니다.
- 사람 및 AI 쌍: 사용자 및 어시스턴트 메시지만 전송합니다(시스템 메시지, 도구 호출 등 제외).
- 첫 번째 사람 및 마지막 AI: 첫 번째 사용자 메시지와 마지막 어시스턴트 응답만 전송합니다.
-
피드백 구성을 설정합니다.
피드백 키의 이름, 수집하려는 피드백 형식을 구성하고 선택적으로 피드백에 대한 추론을 활성화합니다.
- 평가자를 저장합니다.
제한 사항
다음은 다중 턴 온라인 평가자의 현재 제한 사항입니다(변경될 수 있음). 이러한 제한에 도달하는 경우 문의해 주세요.- 실행은 1주일 미만이어야 합니다: 스레드가 유휴 상태가 되면 지난 7일 이내의 실행만 평가 대상이 됩니다.
- 한 번에 최대 500개의 스레드 평가: 5분 기간에 500개 이상의 스레드가 유휴 상태로 표시되면 자동으로 500개를 초과하여 샘플링합니다.
- 작업 공간당 최대 10개의 다중 턴 온라인 평가자
문제 해결
평가자의 상태 확인트레이싱 프로젝트 내의 Evaluators 탭으로 이동하여 생성한 평가자의 Logs 버튼을 클릭하여 실행 기록을 확인함으로써 평가자가 마지막으로 실행된 시기를 확인할 수 있습니다. 평가자에게 전송된 데이터 검사
트레이싱 프로젝트 내의 Evaluators 탭으로 이동하여 생성한 평가자를 클릭한 다음 Evaluator traces 탭을 클릭하여 평가자에게 전송된 데이터를 검사합니다. 이 탭에서 LLM-as-a-judge 평가자에 전달된 입력을 확인할 수 있습니다. 메시지가 올바르게 전달되지 않으면 입력에 빈 값이 표시됩니다. 이는 메시지가 예상 형식 중 하나로 형식화되지 않은 경우 발생할 수 있습니다.