

SQL 데이터베이스의 Q&A 시스템을 구축하려면 모델이 생성한 SQL 쿼리를 실행해야 합니다. 이를 수행하는 데는 본질적인 위험이 존재합니다. 데이터베이스 연결 권한이 에이전트의 필요에 따라 항상 최대한 좁게 범위가 지정되도록 하십시오. 이는 모델 기반 시스템 구축의 위험을 완화하지만 제거하지는 않습니다.
개념
다음 개념들을 다룹니다:- SQL 데이터베이스에서 읽기 위한 도구
- 상태, 노드, 엣지 및 조건부 엣지를 포함하는 LangGraph Graph API
- Human-in-the-loop 프로세스
설정
설치
Copy
pip install langchain langgraph langchain-community
LangSmith
체인 또는 에이전트 내부에서 발생하는 일을 검사하려면 LangSmith를 설정하십시오. 그런 다음 다음 환경 변수를 설정합니다:Copy
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
1. LLM 선택
도구 호출을 지원하는 모델을 선택하십시오:- OpenAI
- Anthropic
- Azure
- Google Gemini
- AWS Bedrock
👉 Read the OpenAI chat model integration docs
Copy
pip install -U "langchain[openai]"
Copy
import os
from langchain.chat_models import init_chat_model
os.environ["OPENAI_API_KEY"] = "sk-..."
model = init_chat_model("openai:gpt-4.1")
👉 Read the Anthropic chat model integration docs
Copy
pip install -U "langchain[anthropic]"
Copy
import os
from langchain.chat_models import init_chat_model
os.environ["ANTHROPIC_API_KEY"] = "sk-..."
model = init_chat_model("anthropic:claude-sonnet-4-5")
👉 Read the Azure chat model integration docs
Copy
pip install -U "langchain[openai]"
Copy
import os
from langchain.chat_models import init_chat_model
os.environ["AZURE_OPENAI_API_KEY"] = "..."
os.environ["AZURE_OPENAI_ENDPOINT"] = "..."
os.environ["OPENAI_API_VERSION"] = "2025-03-01-preview"
model = init_chat_model(
"azure_openai:gpt-4.1",
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
)
👉 Read the Google GenAI chat model integration docs
Copy
pip install -U "langchain[google-genai]"
Copy
import os
from langchain.chat_models import init_chat_model
os.environ["GOOGLE_API_KEY"] = "..."
model = init_chat_model("google_genai:gemini-2.5-flash-lite")
👉 Read the AWS Bedrock chat model integration docs
Copy
pip install -U "langchain[aws]"
Copy
from langchain.chat_models import init_chat_model
# Follow the steps here to configure your credentials:
# https://docs.aws.amazon.com/bedrock/latest/userguide/getting-started.html
model = init_chat_model(
"anthropic.claude-3-5-sonnet-20240620-v1:0",
model_provider="bedrock_converse",
)
2. 데이터베이스 구성
이 튜토리얼에서는 SQLite 데이터베이스를 생성합니다. SQLite는 설정하고 사용하기 쉬운 경량 데이터베이스입니다. 디지털 미디어 스토어를 나타내는 샘플 데이터베이스인chinook 데이터베이스를 로드합니다.
편의를 위해 공용 GCS 버킷에 데이터베이스(Chinook.db)를 호스팅했습니다.
Copy
import requests, pathlib
url = "https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db"
local_path = pathlib.Path("Chinook.db")
if local_path.exists():
print(f"{local_path} already exists, skipping download.")
else:
response = requests.get(url)
if response.status_code == 200:
local_path.write_bytes(response.content)
print(f"File downloaded and saved as {local_path}")
else:
print(f"Failed to download the file. Status code: {response.status_code}")
langchain_community 패키지에서 제공하는 편리한 SQL 데이터베이스 래퍼를 사용합니다. 이 래퍼는 SQL 쿼리를 실행하고 결과를 가져오는 간단한 인터페이스를 제공합니다:
Copy
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(f"Dialect: {db.dialect}")
print(f"Available tables: {db.get_usable_table_names()}")
print(f'Sample output: {db.run("SELECT * FROM Artist LIMIT 5;")}')
Copy
Dialect: sqlite
Available tables: ['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
Sample output: [(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains')]
3. 데이터베이스 상호 작용을 위한 도구 추가
데이터베이스와 상호 작용하기 위해langchain_community 패키지에서 제공하는 SQLDatabase 래퍼를 사용합니다. 이 래퍼는 SQL 쿼리를 실행하고 결과를 가져오는 간단한 인터페이스를 제공합니다:
Copy
from langchain_community.agent_toolkits import SQLDatabaseToolkit
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
tools = toolkit.get_tools()
for tool in tools:
print(f"{tool.name}: {tool.description}\n")
Copy
sql_db_query: Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error message will be returned. If an error is returned, rewrite the query, check the query, and try again. If you encounter an issue with Unknown column 'xxxx' in 'field list', use sql_db_schema to query the correct table fields.
sql_db_schema: Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables. Be sure that the tables actually exist by calling sql_db_list_tables first! Example Input: table1, table2, table3
sql_db_list_tables: Input is an empty string, output is a comma-separated list of tables in the database.
sql_db_query_checker: Use this tool to double check if your query is correct before executing it. Always use this tool before executing a query with sql_db_query!
4. 애플리케이션 단계 정의
다음 단계들을 위한 전용 노드를 구성합니다:- DB 테이블 나열
- “get schema” 도구 호출
- 쿼리 생성
- 쿼리 검사
Copy
from typing import Literal
from langchain.agents import ToolNode
from langchain.messages import AIMessage
from langchain_core.runnables import RunnableConfig
from langgraph.graph import END, START, MessagesState, StateGraph
get_schema_tool = next(tool for tool in tools if tool.name == "sql_db_schema")
get_schema_node = ToolNode([get_schema_tool], name="get_schema")
run_query_tool = next(tool for tool in tools if tool.name == "sql_db_query")
run_query_node = ToolNode([run_query_tool], name="run_query")
# 예제: 미리 결정된 도구 호출 생성
def list_tables(state: MessagesState):
tool_call = {
"name": "sql_db_list_tables",
"args": {},
"id": "abc123",
"type": "tool_call",
}
tool_call_message = AIMessage(content="", tool_calls=[tool_call])
list_tables_tool = next(tool for tool in tools if tool.name == "sql_db_list_tables")
tool_message = list_tables_tool.invoke(tool_call)
response = AIMessage(f"Available tables: {tool_message.content}")
return {"messages": [tool_call_message, tool_message, response]}
# 예제: 모델이 도구 호출을 생성하도록 강제
def call_get_schema(state: MessagesState):
# LangChain은 모든 모델이 `tool_choice="any"`와
# `tool_choice=<도구 이름 문자열>`을 허용하도록 강제합니다.
llm_with_tools = llm.bind_tools([get_schema_tool], tool_choice="any")
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
generate_query_system_prompt = """
당신은 SQL 데이터베이스와 상호 작용하도록 설계된 에이전트입니다.
입력 질문이 주어지면 실행할 구문적으로 올바른 {dialect} 쿼리를 생성하고,
쿼리 결과를 보고 답변을 반환합니다. 사용자가 특정 개수의
예제를 얻고자 한다고 명시하지 않는 한, 항상 쿼리를 최대 {top_k}개의
결과로 제한하십시오.
관련 열을 기준으로 결과를 정렬하여 데이터베이스에서 가장 흥미로운
예제를 반환할 수 있습니다. 특정 테이블의 모든 열을 쿼리하지 말고,
질문에 따라 관련 열만 요청하십시오.
데이터베이스에 대한 DML 문(INSERT, UPDATE, DELETE, DROP 등)을 작성하지 마십시오.
""".format(
dialect=db.dialect,
top_k=5,
)
def generate_query(state: MessagesState):
system_message = {
"role": "system",
"content": generate_query_system_prompt,
}
# 모델이 솔루션을 얻을 때 자연스럽게 응답할 수 있도록
# 여기서 도구 호출을 강제하지 않습니다.
llm_with_tools = llm.bind_tools([run_query_tool])
response = llm_with_tools.invoke([system_message] + state["messages"])
return {"messages": [response]}
check_query_system_prompt = """
당신은 세부 사항에 강한 주의를 기울이는 SQL 전문가입니다.
다음과 같은 일반적인 실수가 있는지 {dialect} 쿼리를 다시 확인하십시오:
- NULL 값과 함께 NOT IN 사용
- UNION ALL을 사용해야 할 때 UNION 사용
- 배타적 범위에 BETWEEN 사용
- 술어의 데이터 타입 불일치
- 식별자를 올바르게 인용하지 않음
- 함수에 올바른 인수 개수를 사용하지 않음
- 올바른 데이터 타입으로 캐스팅하지 않음
- 조인에 적절한 열을 사용하지 않음
위의 실수가 있는 경우 쿼리를 다시 작성하십시오. 실수가 없는 경우
원래 쿼리를 그대로 재생성하십시오.
이 검사를 실행한 후 적절한 도구를 호출하여 쿼리를 실행합니다.
""".format(dialect=db.dialect)
def check_query(state: MessagesState):
system_message = {
"role": "system",
"content": check_query_system_prompt,
}
# 검사할 인위적인 사용자 메시지 생성
tool_call = state["messages"][-1].tool_calls[0]
user_message = {"role": "user", "content": tool_call["args"]["query"]}
llm_with_tools = llm.bind_tools([run_query_tool], tool_choice="any")
response = llm_with_tools.invoke([system_message, user_message])
response.id = state["messages"][-1].id
return {"messages": [response]}
5. 에이전트 구현
이제 Graph API를 사용하여 이러한 단계들을 워크플로우로 조합할 수 있습니다. 쿼리 생성 단계에서 조건부 엣지를 정의하여 쿼리가 생성되면 쿼리 검사기로 라우팅하거나, LLM이 쿼리에 대한 응답을 전달한 경우와 같이 도구 호출이 없으면 종료하도록 합니다.Copy
def should_continue(state: MessagesState) -> Literal[END, "check_query"]:
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return END
else:
return "check_query"
builder = StateGraph(MessagesState)
builder.add_node(list_tables)
builder.add_node(call_get_schema)
builder.add_node(get_schema_node, "get_schema")
builder.add_node(generate_query)
builder.add_node(check_query)
builder.add_node(run_query_node, "run_query")
builder.add_edge(START, "list_tables")
builder.add_edge("list_tables", "call_get_schema")
builder.add_edge("call_get_schema", "get_schema")
builder.add_edge("get_schema", "generate_query")
builder.add_conditional_edges(
"generate_query",
should_continue,
)
builder.add_edge("check_query", "run_query")
builder.add_edge("run_query", "generate_query")
agent = builder.compile()
Copy
from IPython.display import Image, display
from langchain_core.runnables.graph import CurveStyle, MermaidDrawMethod, NodeStyles
display(Image(agent.get_graph().draw_mermaid_png()))
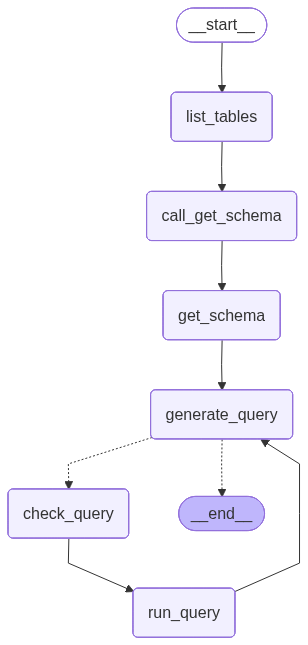
Copy
question = "Which genre on average has the longest tracks?"
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()
Copy
================================ Human Message =================================
Which genre on average has the longest tracks?
================================== Ai Message ==================================
Available tables: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
================================== Ai Message ==================================
Tool Calls:
sql_db_schema (call_yzje0tj7JK3TEzDx4QnRR3lL)
Call ID: call_yzje0tj7JK3TEzDx4QnRR3lL
Args:
table_names: Genre, Track
================================= Tool Message =================================
Name: sql_db_schema
CREATE TABLE "Genre" (
"GenreId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("GenreId")
)
/*
3 rows from Genre table:
GenreId Name
1 Rock
2 Jazz
3 Metal
*/
CREATE TABLE "Track" (
"TrackId" INTEGER NOT NULL,
"Name" NVARCHAR(200) NOT NULL,
"AlbumId" INTEGER,
"MediaTypeId" INTEGER NOT NULL,
"GenreId" INTEGER,
"Composer" NVARCHAR(220),
"Milliseconds" INTEGER NOT NULL,
"Bytes" INTEGER,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("TrackId"),
FOREIGN KEY("MediaTypeId") REFERENCES "MediaType" ("MediaTypeId"),
FOREIGN KEY("GenreId") REFERENCES "Genre" ("GenreId"),
FOREIGN KEY("AlbumId") REFERENCES "Album" ("AlbumId")
)
/*
3 rows from Track table:
TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice
1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.99
2 Balls to the Wall 2 2 1 U. Dirkschneider, W. Hoffmann, H. Frank, P. Baltes, S. Kaufmann, G. Hoffmann 342562 5510424 0.99
3 Fast As a Shark 3 2 1 F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman 230619 3990994 0.99
*/
================================== Ai Message ==================================
Tool Calls:
sql_db_query (call_cb9ApLfZLSq7CWg6jd0im90b)
Call ID: call_cb9ApLfZLSq7CWg6jd0im90b
Args:
query: SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgMilliseconds FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.GenreId ORDER BY AvgMilliseconds DESC LIMIT 5;
================================== Ai Message ==================================
Tool Calls:
sql_db_query (call_DMVALfnQ4kJsuF3Yl6jxbeAU)
Call ID: call_DMVALfnQ4kJsuF3Yl6jxbeAU
Args:
query: SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgMilliseconds FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.GenreId ORDER BY AvgMilliseconds DESC LIMIT 5;
================================= Tool Message =================================
Name: sql_db_query
[('Sci Fi & Fantasy', 2911783.0384615385), ('Science Fiction', 2625549.076923077), ('Drama', 2575283.78125), ('TV Shows', 2145041.0215053763), ('Comedy', 1585263.705882353)]
================================== Ai Message ==================================
The genre with the longest tracks on average is "Sci Fi & Fantasy," with an average track length of approximately 2,911,783 milliseconds. Other genres with relatively long tracks include "Science Fiction," "Drama," "TV Shows," and "Comedy."
위 실행에 대한 LangSmith 추적을 참조하십시오.
6. Human-in-the-loop 검토 구현
에이전트의 SQL 쿼리가 실행되기 전에 의도하지 않은 작업이나 비효율성을 확인하는 것이 현명할 수 있습니다. 여기서는 LangGraph의 human-in-the-loop 기능을 활용하여 SQL 쿼리를 실행하기 전에 실행을 일시 중지하고 사람의 검토를 기다립니다. LangGraph의 지속성 레이어를 사용하여 무기한(또는 최소한 지속성 레이어가 살아있는 한) 실행을 일시 중지할 수 있습니다. 사람의 입력을 받는 노드에서sql_db_query 도구를 래핑해 봅시다. interrupt 함수를 사용하여 이를 구현할 수 있습니다. 아래에서는 도구 호출을 승인하거나, 인수를 편집하거나, 사용자 피드백을 제공할 수 있는 입력을 허용합니다.
Copy
from langchain_core.runnables import RunnableConfig
from langchain.tools import tool
from langgraph.types import interrupt
@tool(
run_query_tool.name,
description=run_query_tool.description,
args_schema=run_query_tool.args_schema
)
def run_query_tool_with_interrupt(config: RunnableConfig, **tool_input):
request = {
"action": run_query_tool.name,
"args": tool_input,
"description": "Please review the tool call"
}
response = interrupt([request])
# 도구 호출 승인
if response["type"] == "accept":
tool_response = run_query_tool.invoke(tool_input, config)
# 도구 호출 인수 업데이트
elif response["type"] == "edit":
tool_input = response["args"]["args"]
tool_response = run_query_tool.invoke(tool_input, config)
# 사용자 피드백과 함께 LLM에 응답
elif response["type"] == "response":
user_feedback = response["args"]
tool_response = user_feedback
else:
raise ValueError(f"Unsupported interrupt response type: {response['type']}")
return tool_response
위 구현은 더 광범위한 human-in-the-loop 가이드의 도구 인터럽트 예제를 따릅니다. 자세한 내용과 대안은 해당 가이드를 참조하십시오.
Copy
from langgraph.checkpoint.memory import InMemorySaver
def should_continue(state: MessagesState) -> Literal[END, "run_query"]:
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return END
else:
return "run_query"
builder = StateGraph(MessagesState)
builder.add_node(list_tables)
builder.add_node(call_get_schema)
builder.add_node(get_schema_node, "get_schema")
builder.add_node(generate_query)
builder.add_node(run_query_node, "run_query")
builder.add_edge(START, "list_tables")
builder.add_edge("list_tables", "call_get_schema")
builder.add_edge("call_get_schema", "get_schema")
builder.add_edge("get_schema", "generate_query")
builder.add_conditional_edges(
"generate_query",
should_continue,
)
builder.add_edge("run_query", "generate_query")
checkpointer = InMemorySaver()
agent = builder.compile(checkpointer=checkpointer)
Copy
import json
config = {"configurable": {"thread_id": "1"}}
question = "Which genre on average has the longest tracks?"
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
config,
stream_mode="values",
):
if "messages" in step:
step["messages"][-1].pretty_print()
elif "__interrupt__" in step:
action = step["__interrupt__"][0]
print("INTERRUPTED:")
for request in action.value:
print(json.dumps(request, indent=2))
else:
pass
Copy
...
INTERRUPTED:
{
"action": "sql_db_query",
"args": {
"query": "SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgLength FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.Name ORDER BY AvgLength DESC LIMIT 5;"
},
"description": "Please review the tool call"
}
Copy
from langgraph.types import Command
for step in agent.stream(
Command(resume={"type": "accept"}),
# Command(resume={"type": "edit", "args": {"query": "..."}}),
config,
stream_mode="values",
):
if "messages" in step:
step["messages"][-1].pretty_print()
elif "__interrupt__" in step:
action = step["__interrupt__"][0]
print("INTERRUPTED:")
for request in action.value:
print(json.dumps(request, indent=2))
else:
pass
Copy
================================== Ai Message ==================================
Tool Calls:
sql_db_query (call_t4yXkD6shwdTPuelXEmY3sAY)
Call ID: call_t4yXkD6shwdTPuelXEmY3sAY
Args:
query: SELECT Genre.Name, AVG(Track.Milliseconds) AS AvgLength FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId GROUP BY Genre.Name ORDER BY AvgLength DESC LIMIT 5;
================================= Tool Message =================================
Name: sql_db_query
[('Sci Fi & Fantasy', 2911783.0384615385), ('Science Fiction', 2625549.076923077), ('Drama', 2575283.78125), ('TV Shows', 2145041.0215053763), ('Comedy', 1585263.705882353)]
================================== Ai Message ==================================
The genre with the longest average track length is "Sci Fi & Fantasy" with an average length of about 2,911,783 milliseconds. Other genres with long average track lengths include "Science Fiction," "Drama," "TV Shows," and "Comedy."
다음 단계
이와 같은 SQL 에이전트를 포함한 LangGraph 애플리케이션을 LangSmith를 사용하여 평가하는 방법은 그래프 평가하기 가이드를 확인하십시오.Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.