

Python에서 대규모 평가 작업을 실행할 때는 evaluate()의 비동기 버전인 aevaluate() 사용을 권장합니다. 두 메서드는 동일한 인터페이스를 가지고 있으므로, 비동기로 평가 실행하기 가이드를 읽기 전에 이 가이드를 먼저 읽는 것이 좋습니다.JS/TS에서는 evaluate()가 이미 비동기이므로 별도의 메서드가 필요하지 않습니다.또한 대규모 작업을 실행할 때는
max_concurrency/maxConcurrency 인수를 설정하는 것이 중요합니다. 이는 데이터셋을 스레드로 분할하여 평가를 병렬화합니다.애플리케이션 정의하기
먼저 평가할 애플리케이션이 필요합니다. 이 예제에서는 간단한 독성 분류기를 만들어 보겠습니다.데이터셋 생성 또는 선택하기
애플리케이션을 평가하기 위한 데이터셋이 필요합니다. 우리의 데이터셋에는 독성 텍스트와 비독성 텍스트의 레이블이 지정된 예제가 포함됩니다.langsmith>=0.3.13 필요
평가자 정의하기
일반적인 사전 구축된 평가자를 확인하려면 LangChain의 오픈 소스 평가 패키지인 openevals도 확인해 보세요.
- Python:
langsmith>=0.3.13필요 - TypeScript:
langsmith>=0.2.9필요
평가 실행하기
평가를 실행하기 위해 evaluate() / aevaluate() 메서드를 사용합니다. 주요 인수는 다음과 같습니다:- 입력 딕셔너리를 받아 출력 딕셔너리를 반환하는 타겟 함수. 각 예제의
example.inputs필드가 타겟 함수에 전달됩니다. 이 경우toxicity_classifier는 이미 예제 입력을 받도록 설정되어 있으므로 직접 사용할 수 있습니다. data- 평가할 LangSmith 데이터셋의 이름 또는 UUID, 또는 예제의 이터레이터evaluators- 함수의 출력을 점수화할 평가자 목록
langsmith>=0.3.13 필요
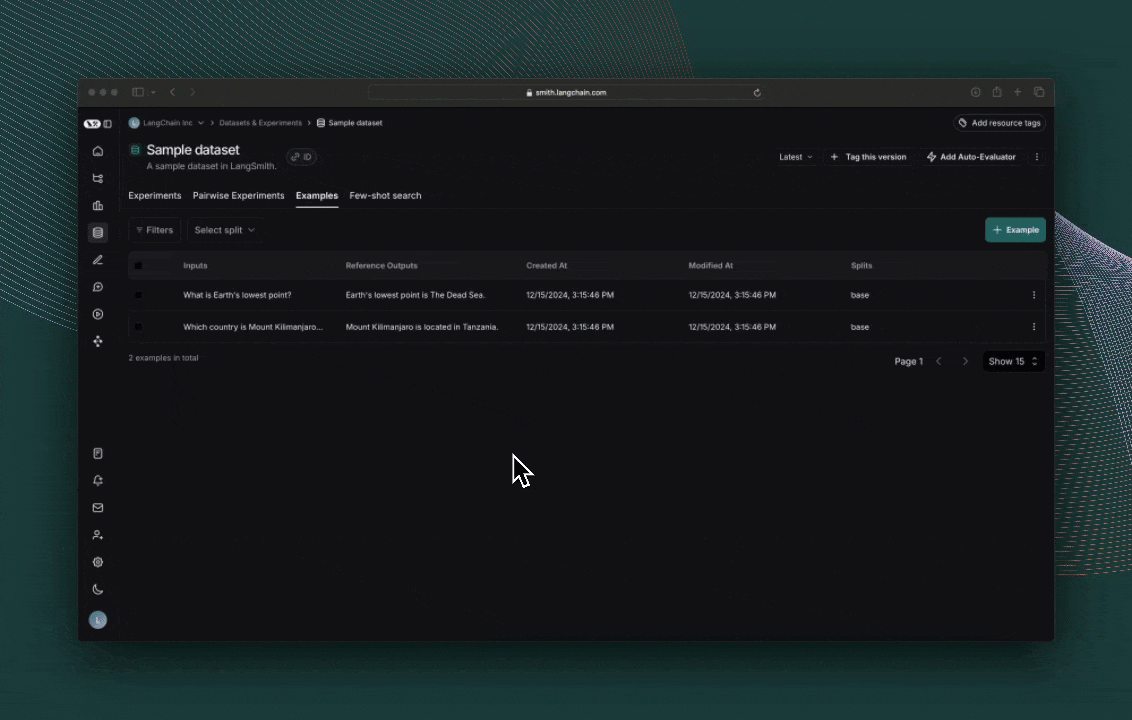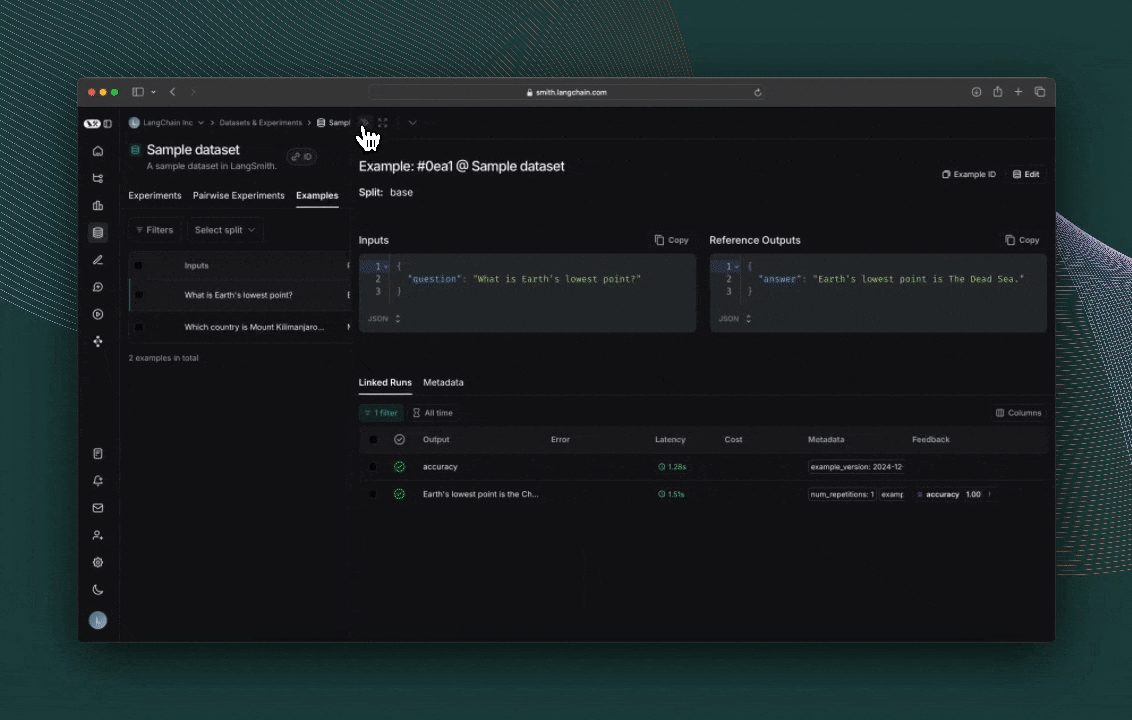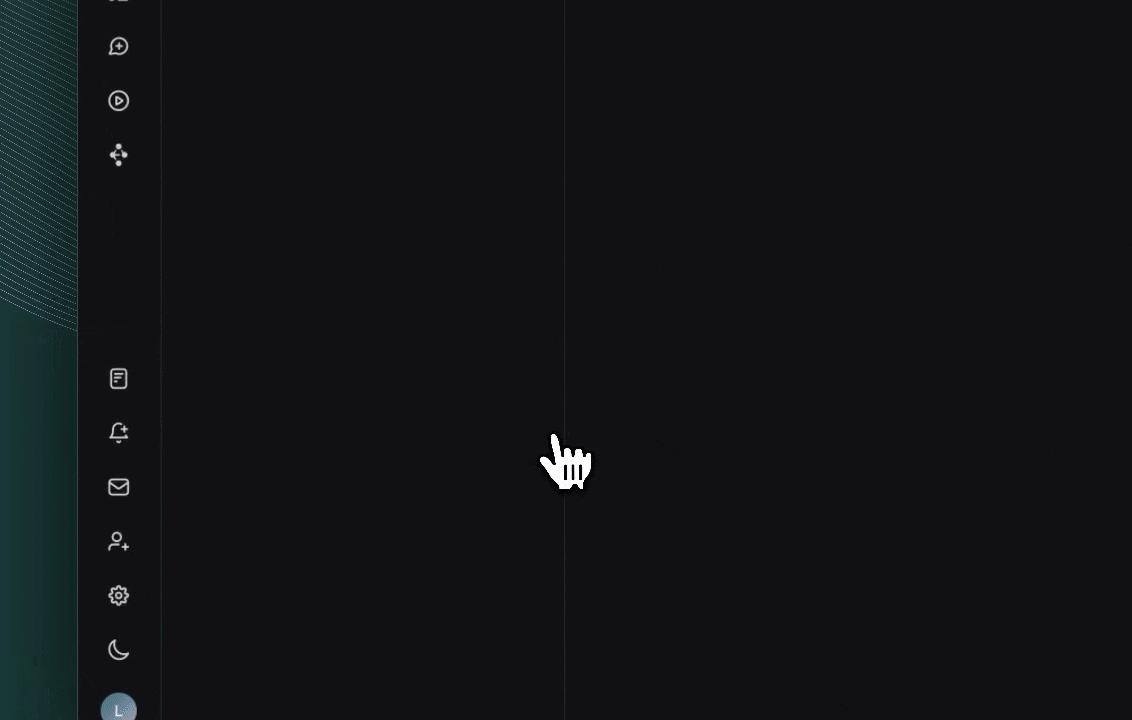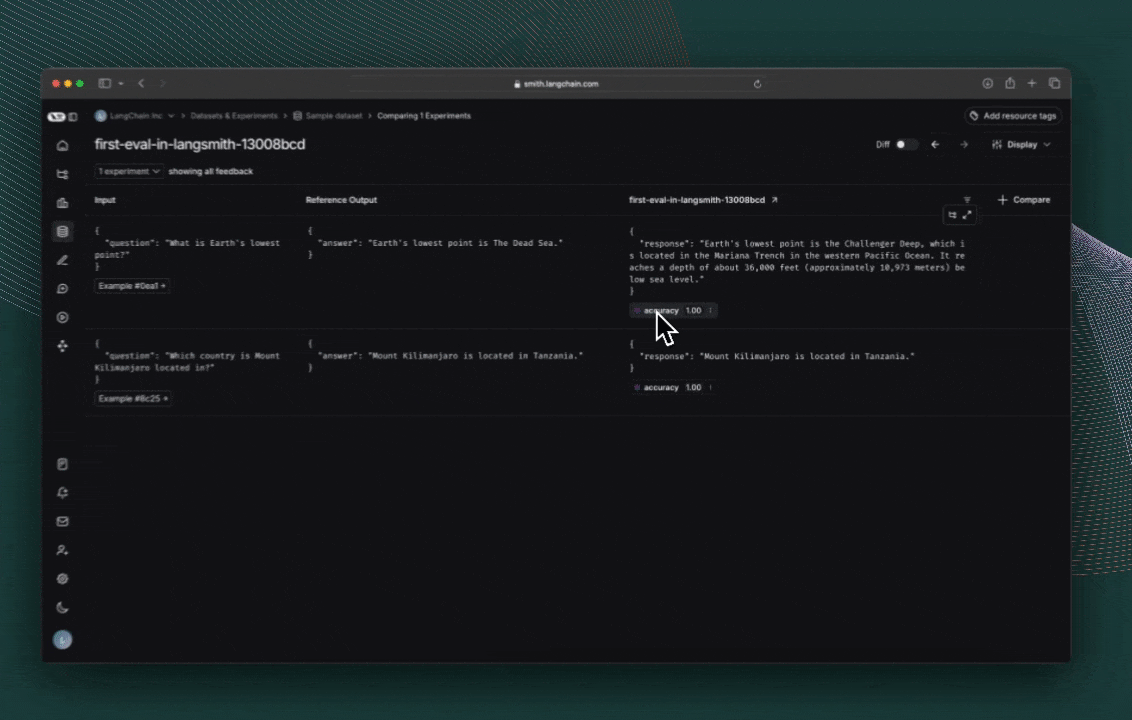
결과 탐색하기
evaluate()의 각 호출은 실험을 생성하며, LangSmith UI에서 확인하거나 SDK를 통해 쿼리할 수 있습니다. 평가 점수는 각 실제 출력에 대한 피드백으로 저장됩니다.
추적을 위해 코드에 주석을 달았다면, 각 행의 추적을 사이드 패널 뷰에서 열 수 있습니다.
참조 코드
통합 코드 스니펫 보기
통합 코드 스니펫 보기