올바른 형식으로 리트리버 트레이스를 기록하지 않아도 문제가 발생하지 않으며, 데이터는 여전히 기록됩니다. 다만 데이터가 리트리버 단계에 특화된 방식으로 렌더링되지 않습니다.
-
리트리버 단계에
run_type="retriever" 어노테이션을 추가합니다.
-
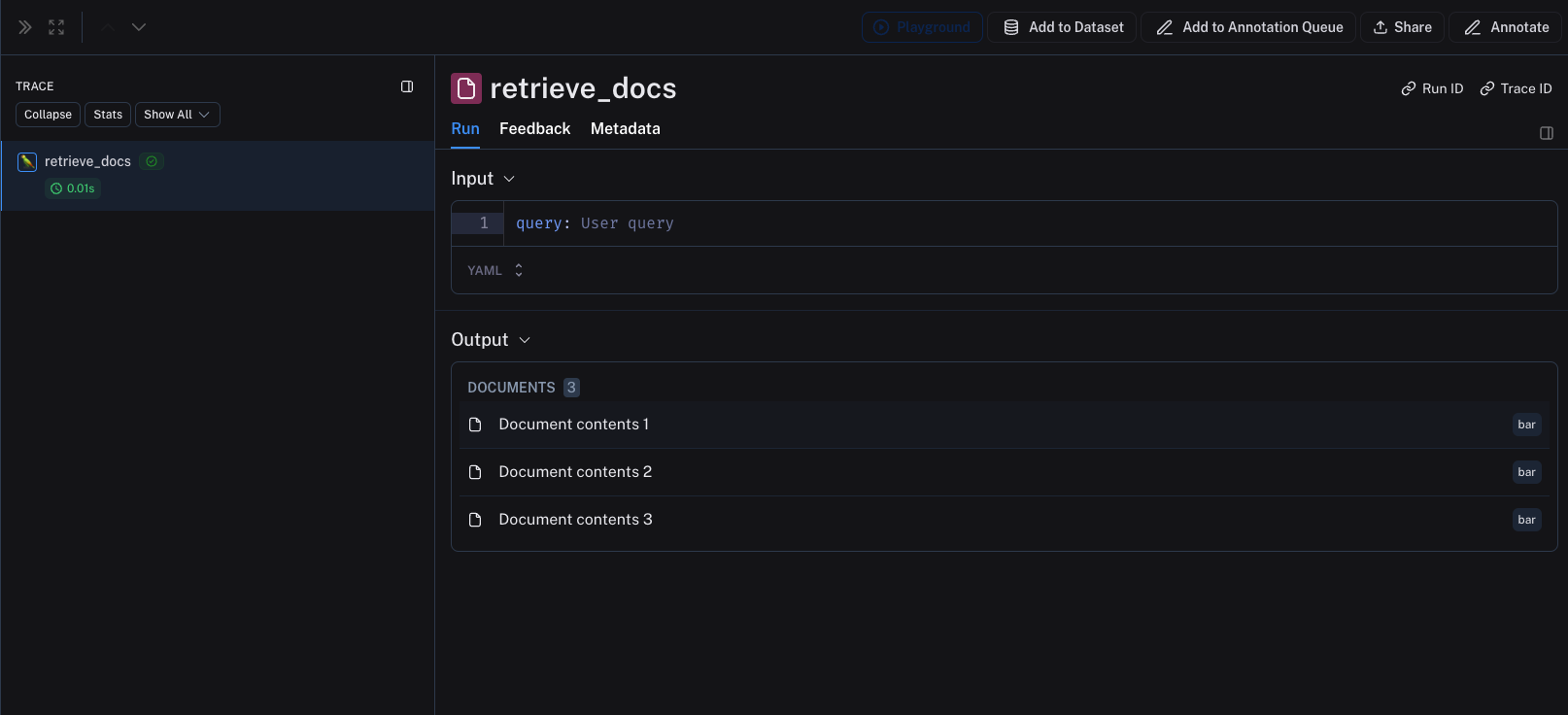
리트리버 단계에서 Python 딕셔너리 또는 TypeScript 객체의 리스트를 반환합니다. 각 딕셔너리는 다음 키를 포함해야 합니다:
page_content: 문서의 텍스트입니다.type: 이 값은 항상 “Document”이어야 합니다.metadata: 문서에 대한 메타데이터를 포함하는 Python 딕셔너리 또는 TypeScript 객체입니다. 이 메타데이터는 트레이스에 표시됩니다.
다음 코드 스니펫은 Python과 TypeScript에서 검색 단계를 기록하는 방법을 보여줍니다.
from langsmith import traceable
def _convert_docs(results):
return [
{
"page_content": r,
"type": "Document",
"metadata": {"foo": "bar"}
}
for r in results
]
@traceable(run_type="retriever")
def retrieve_docs(query):
# Foo retriever returning hardcoded dummy documents.
# In production, this could be a real vector datatabase or other document index.
contents = ["Document contents 1", "Document contents 2", "Document contents 3"]
return _convert_docs(contents)
retrieve_docs("User query")