이 페이지를 진행하기 전에 다음 내용을 읽어보는 것이 도움이 될 수 있습니다:
작동 방식
LangSmith의 평가자 정렬(Align Evaluator) 기능은 인간 전문가 피드백과 LLM-as-a-judge 평가자를 정렬하는 데 도움이 되는 일련의 단계를 제공합니다. 이 기능을 사용하여 오프라인 평가를 위한 데이터셋에서 실행되는 평가자나 온라인 평가를 위한 평가자를 정렬할 수 있습니다. 어느 경우든 단계는 유사합니다:- 애플리케이션의 출력을 포함하는 실험 또는 실행을 선택합니다.
- 선택한 실험 또는 실행을 인간 전문가가 데이터에 레이블을 지정할 수 있는 주석 큐에 추가합니다.
- 레이블이 지정된 예제에 대해 LLM-as-a-judge 평가자 프롬프트를 테스트합니다. 평가자 결과가 레이블이 지정된 데이터와 일치하지 않는 사례를 확인합니다. 이는 평가자 프롬프트를 개선해야 하는 영역을 나타냅니다.
- 평가자 정렬을 개선하기 위해 개선하고 반복합니다. LLM-as-a-judge 평가자 프롬프트를 업데이트하고 다시 테스트합니다.
사전 요구 사항
오프라인 평가 또는 온라인 평가를 위해 이 가이드를 시작하기 전에 다음이 필요합니다:오프라인 평가
온라인 평가
- LangSmith로 이미 트레이스를 전송하고 있는 애플리케이션.
- 시작하려면 추적 통합 중 하나로 구성하세요.
시작하기
데이터셋 및 추적 프로젝트에서 신규 및 기존 평가자 모두에 대해 정렬 플로우에 진입할 수 있습니다.| 데이터셋 평가자 | 추적 프로젝트 평가자 | |
|---|---|---|
| 처음부터 정렬된 평가자 생성 | 1. 데이터셋 및 실험으로 이동하여 데이터셋을 선택합니다 2. + 평가자 > 레이블이 지정된 데이터로부터 생성을 클릭합니다 3. 설명이 포함된 피드백 키 이름을 입력합니다(예: correctness, hallucination) | 1. 프로젝트로 이동하여 프로젝트를 선택합니다 2. + 새로 만들기 > 평가자 > 레이블이 지정된 데이터로부터 생성을 클릭합니다 3. 설명이 포함된 피드백 키 이름을 입력합니다(예: correctness, hallucination) |
| 기존 평가자 정렬 | 1. 데이터셋 및 실험 > 데이터셋 선택 > 평가자 탭 2. 실험 데이터로 평가자 정렬 상자에서 실험 선택을 클릭합니다 | 1. 프로젝트 > 프로젝트 선택 > 평가자 탭 2. 실험 데이터로 평가자 정렬 상자에서 실험 선택을 클릭합니다 |
1. 실험 또는 실행 선택
인간 레이블링을 위해 전송할 하나 이상의 실험(또는 실행)을 선택합니다. 이렇게 하면 주석 큐에 실행이 추가됩니다.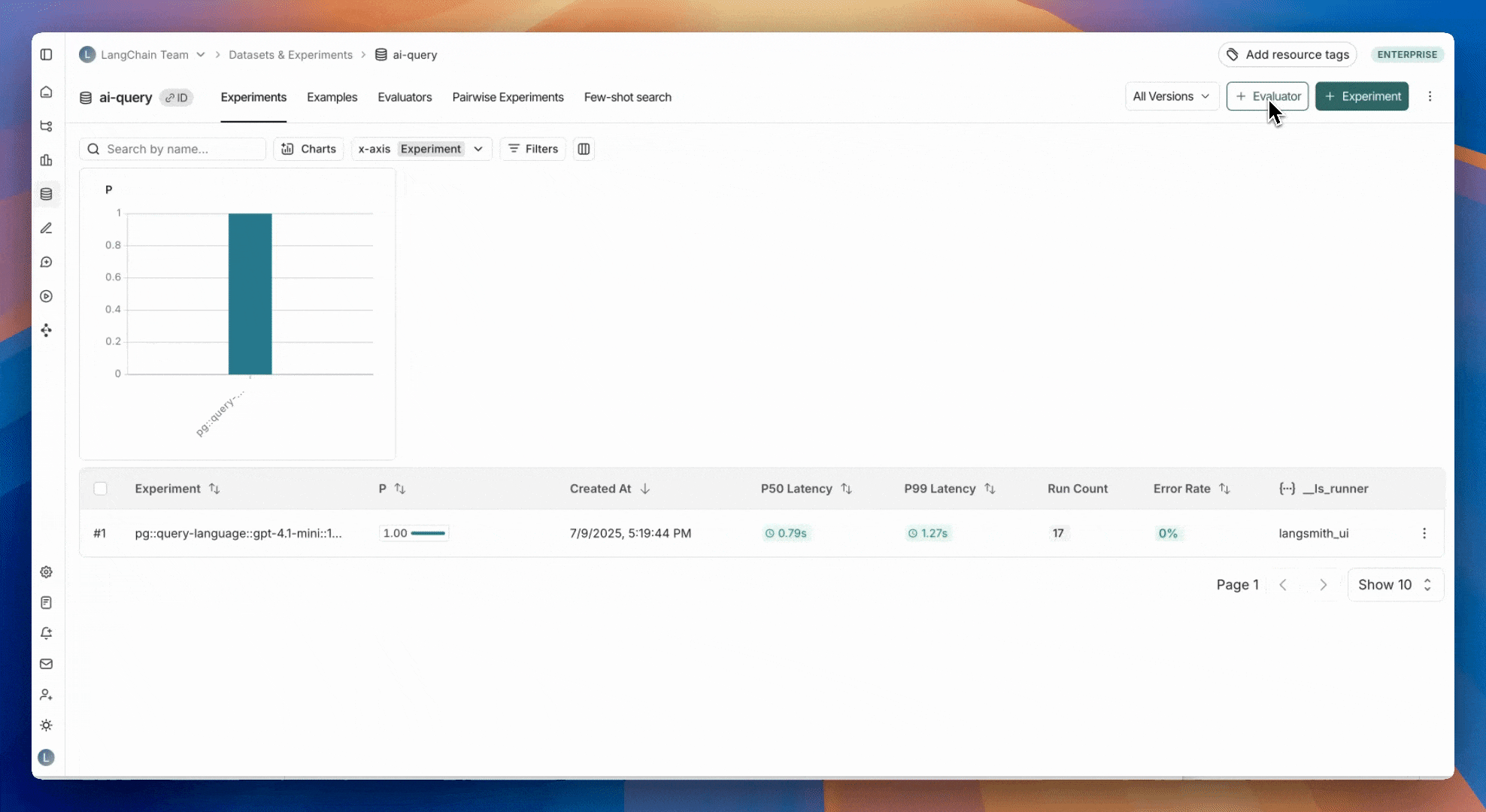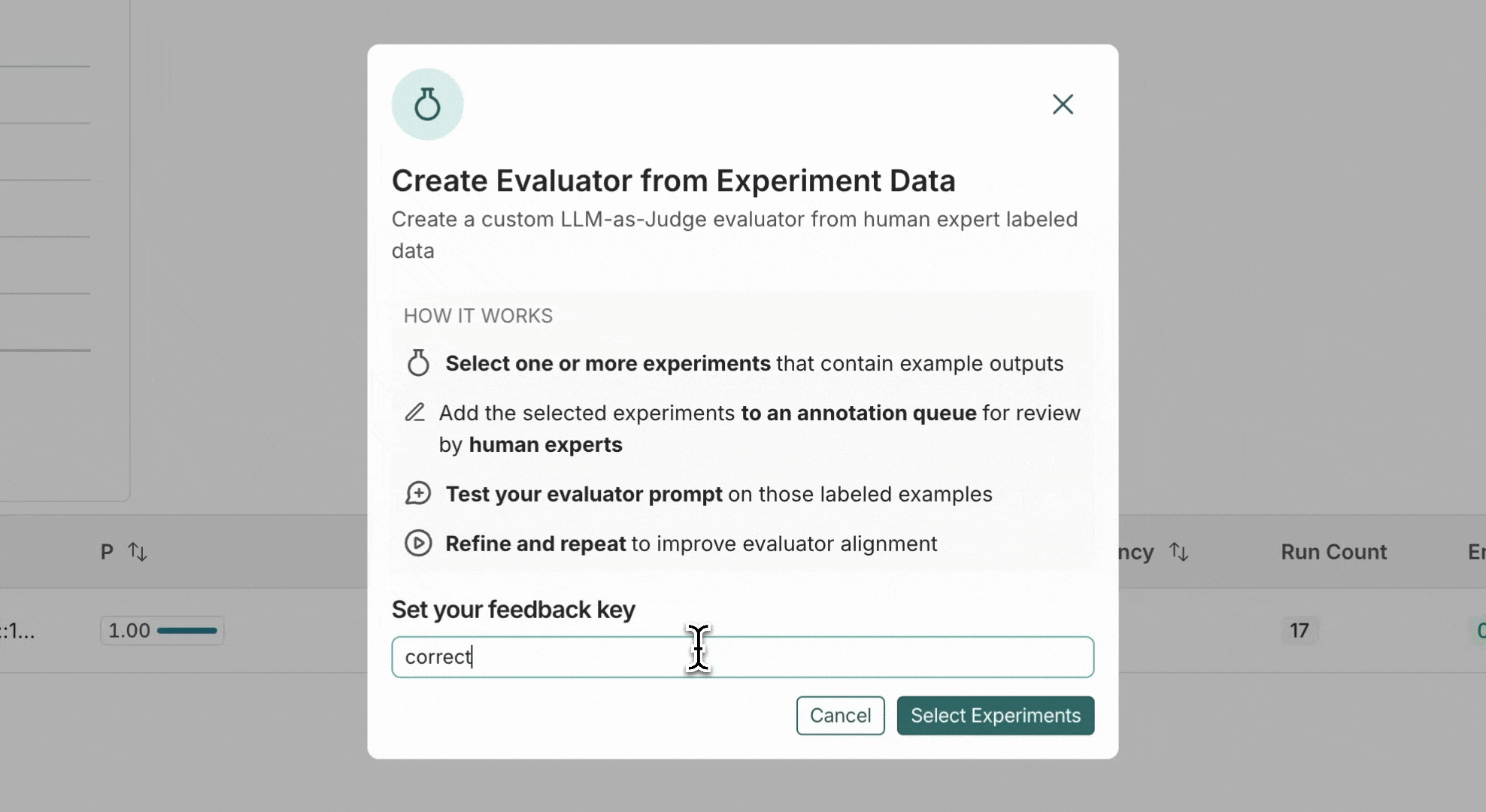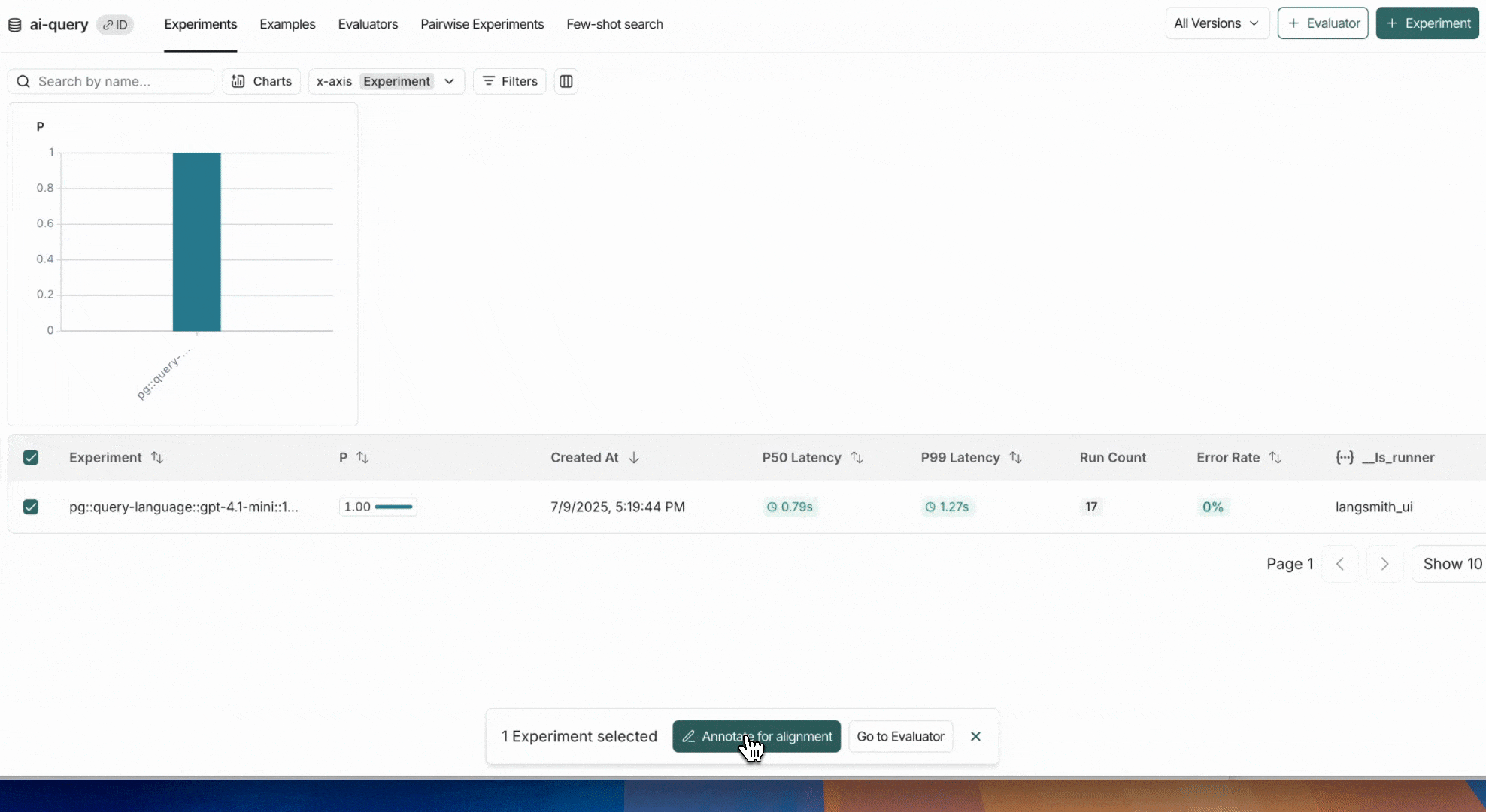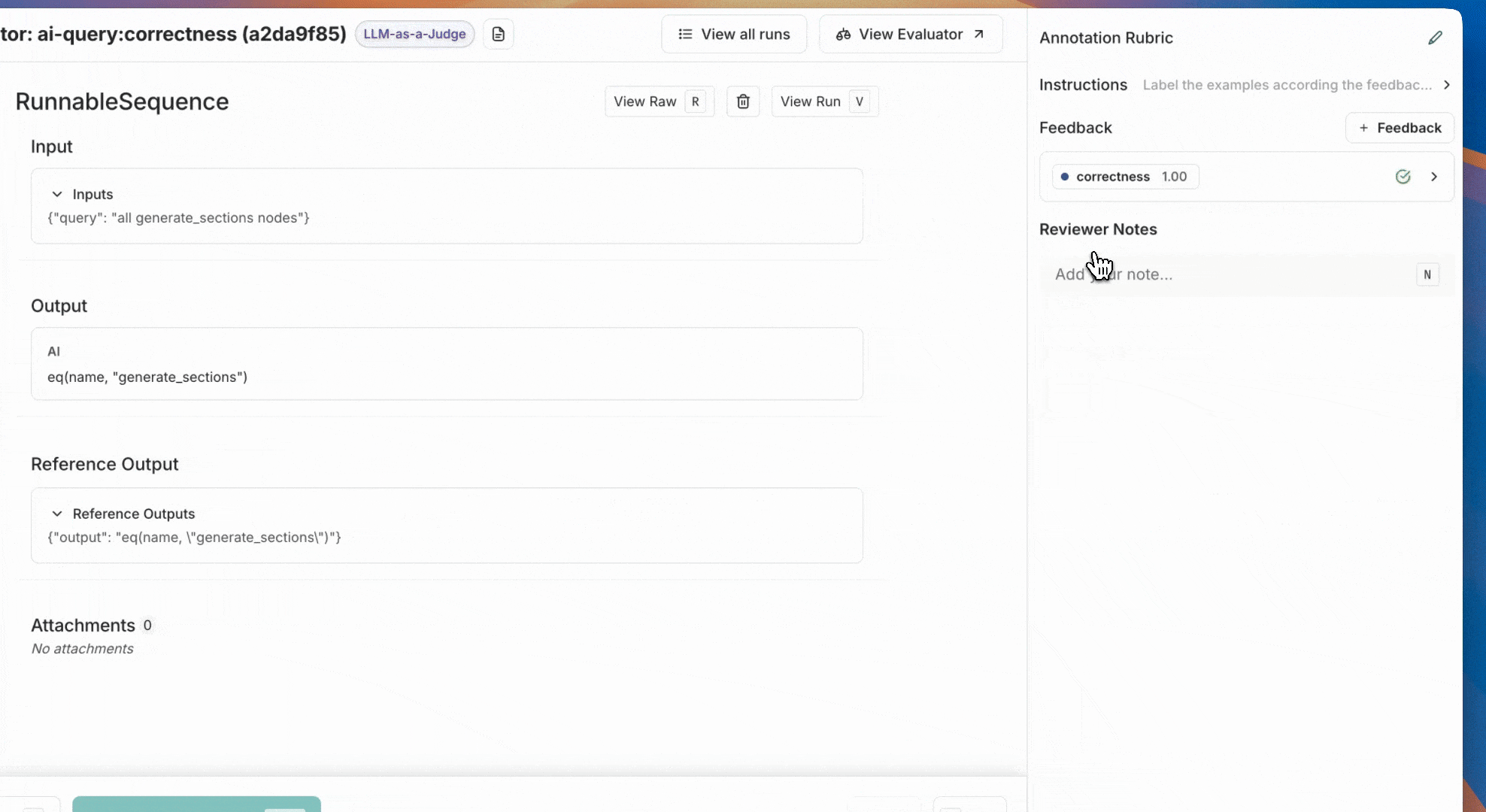
데이터셋은 프로덕션 환경에서 예상되는 입력과 출력을 대표해야 합니다.모든 가능한 시나리오를 다룰 필요는 없지만, 예상되는 모든 사용 사례 범위에 걸친 예제를 포함하는 것이 중요합니다. 예를 들어, 야구, 농구, 축구에 대한 질문에 답하는 스포츠 봇을 구축하는 경우, 데이터셋에는 각 스포츠에서 적어도 하나의 레이블이 지정된 예제가 포함되어야 합니다.
2. 예제에 레이블 지정
피드백 점수를 추가하여 주석 큐의 예제에 레이블을 지정합니다. 예제에 레이블을 지정한 후 참조 데이터셋에 추가를 클릭합니다.실험에 많은 수의 예제가 있는 경우 시작하기 위해 모든 예제에 레이블을 지정할 필요는 없습니다. 최소 20개의 예제로 시작하는 것을 권장하며, 나중에 언제든지 더 추가할 수 있습니다. 레이블을 지정하는 예제가 다양해야 하며(0과 1 레이블 모두 균형 있게), 잘 균형 잡힌 평가자 프롬프트를 구축할 수 있도록 하는 것을 권장합니다.
3. 레이블이 지정된 예제에 대해 평가자 프롬프트 테스트
레이블이 지정된 예제가 있으면 다음 단계는 레이블이 지정된 데이터를 최대한 모방하도록 평가자 프롬프트를 반복하는 것입니다. 이 반복은 평가자 플레이그라운드에서 수행됩니다. 평가자 플레이그라운드로 이동하려면: 평가자 큐의 오른쪽 상단에 있는 평가자 보기 버튼을 클릭합니다. 그러면 정렬 중인 평가자의 세부 정보 페이지로 이동합니다. 평가자 플레이그라운드 버튼을 클릭하여 플레이그라운드에 액세스합니다.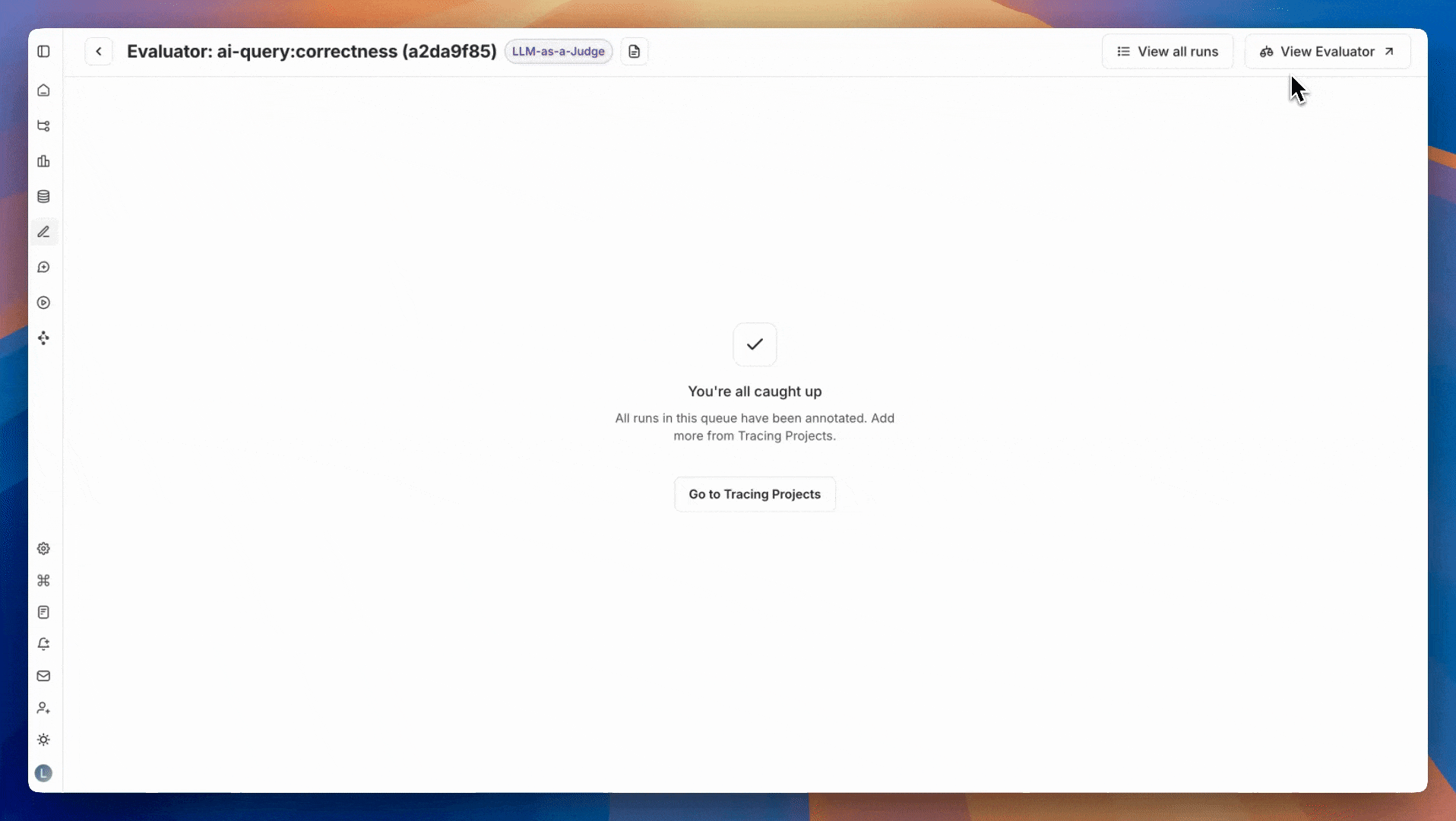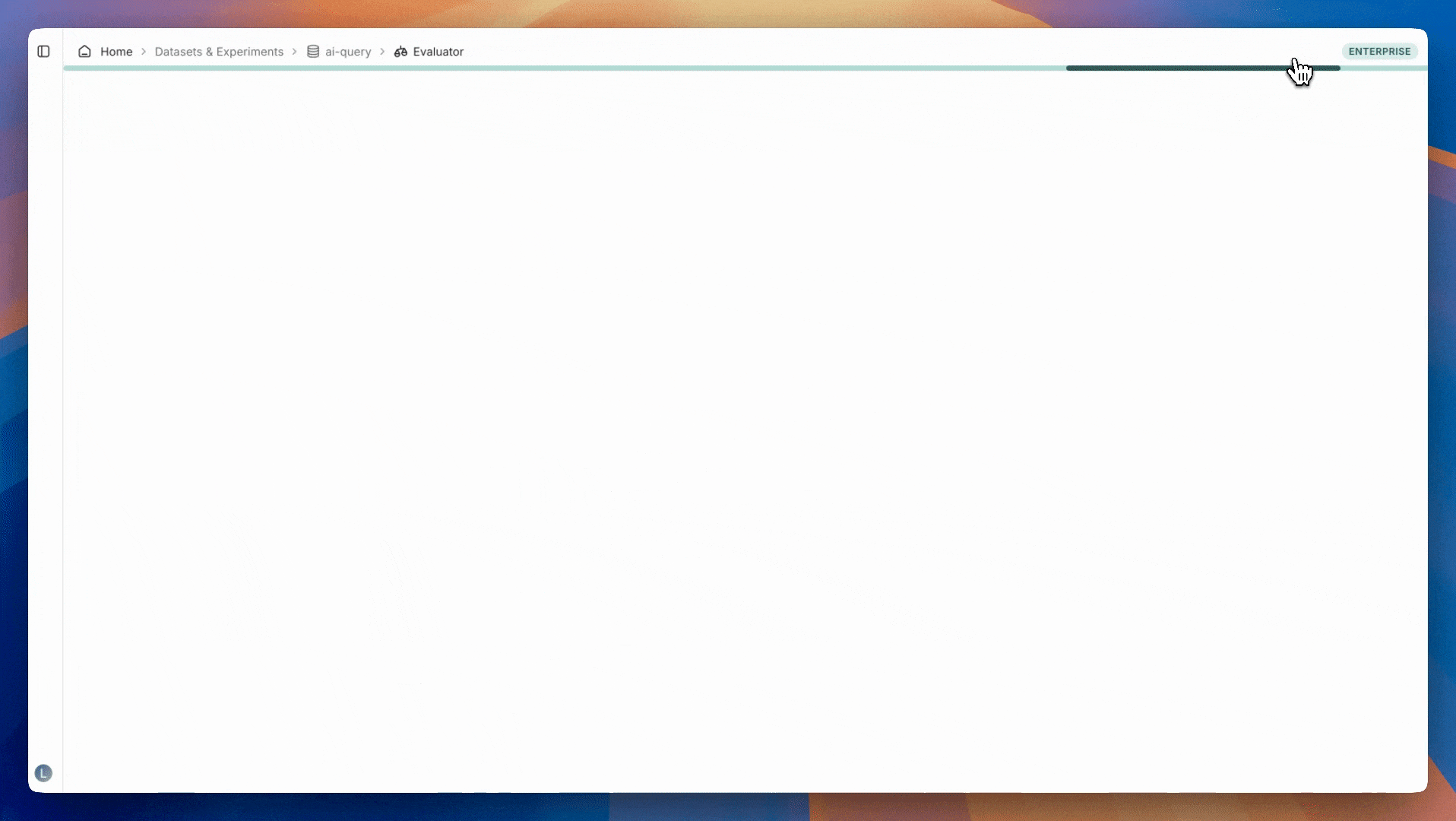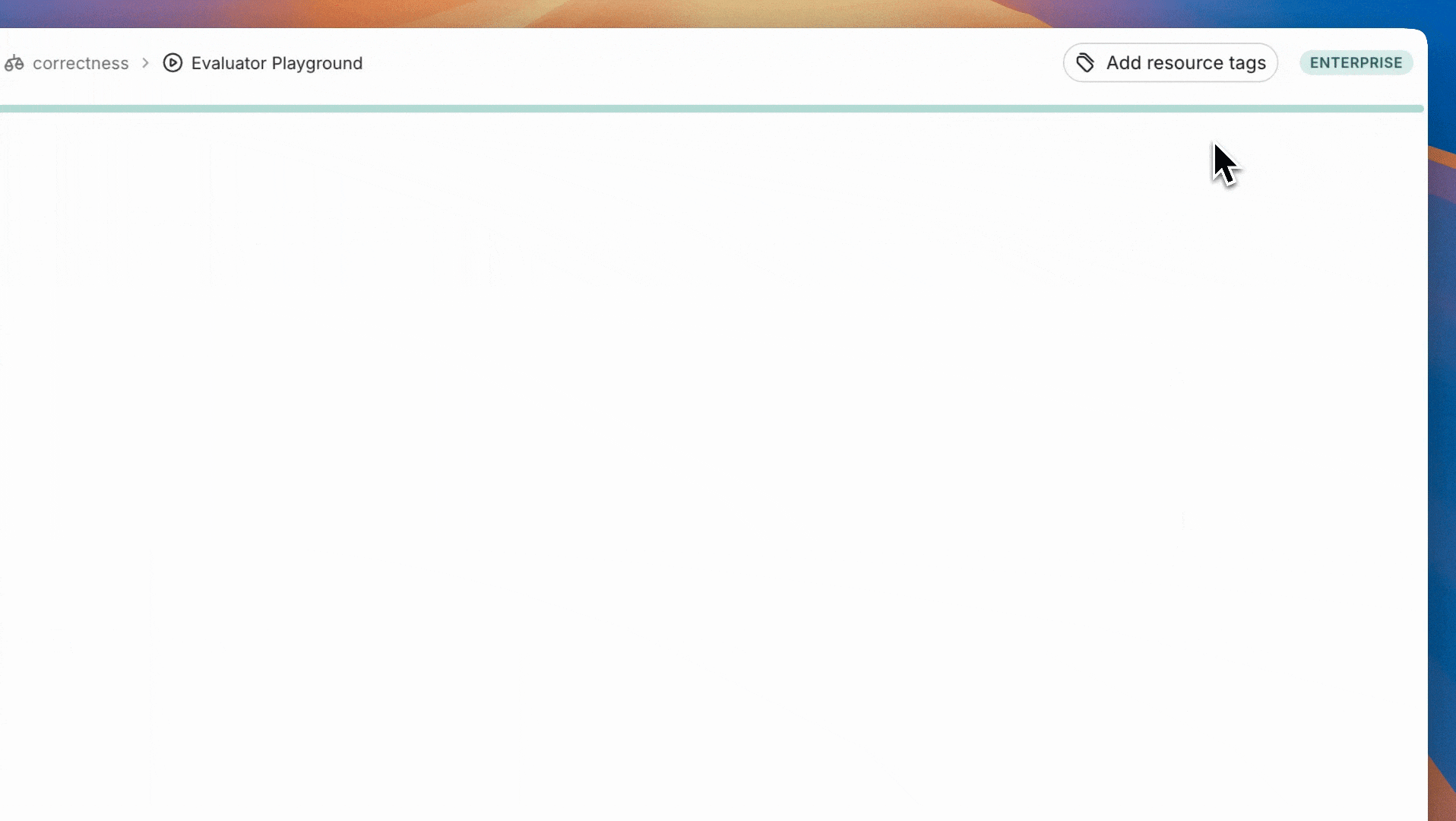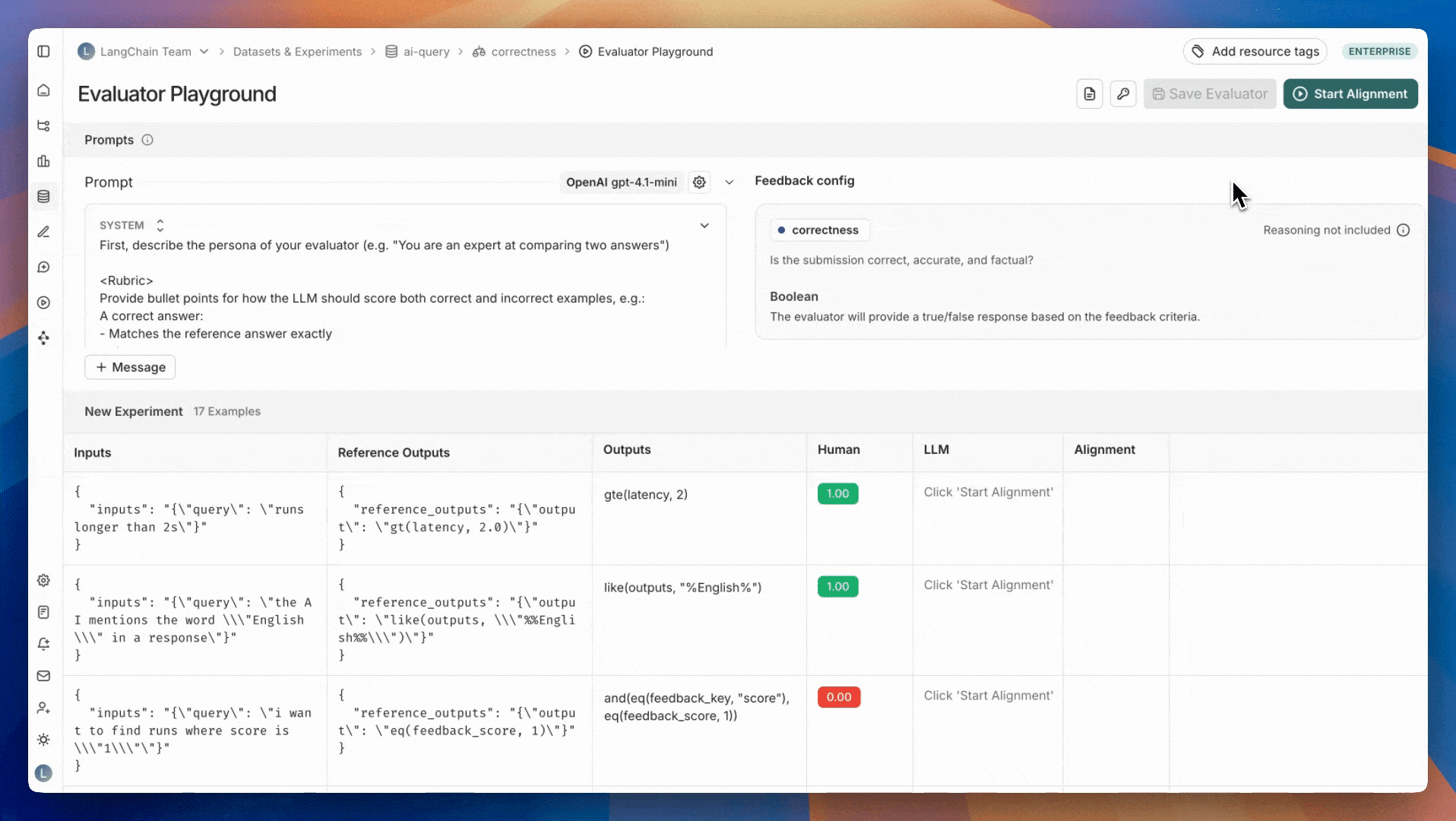

4. 평가자 정렬을 개선하기 위해 반복
평가자 정렬을 개선하기 위해 프롬프트를 업데이트하고 다시 테스트하여 반복합니다.평가자 프롬프트에 대한 업데이트는 기본적으로 저장되지 않습니다. 정기적으로, 특히 정렬 점수가 개선된 것을 확인한 후에는 평가자 프롬프트를 저장하는 것을 권장합니다.평가자 플레이그라운드는 프롬프트를 반복할 때 비교를 위해 가장 최근에 저장된 평가자 프롬프트 버전의 정렬 점수를 표시합니다.
평가자 정렬 개선을 위한 팁
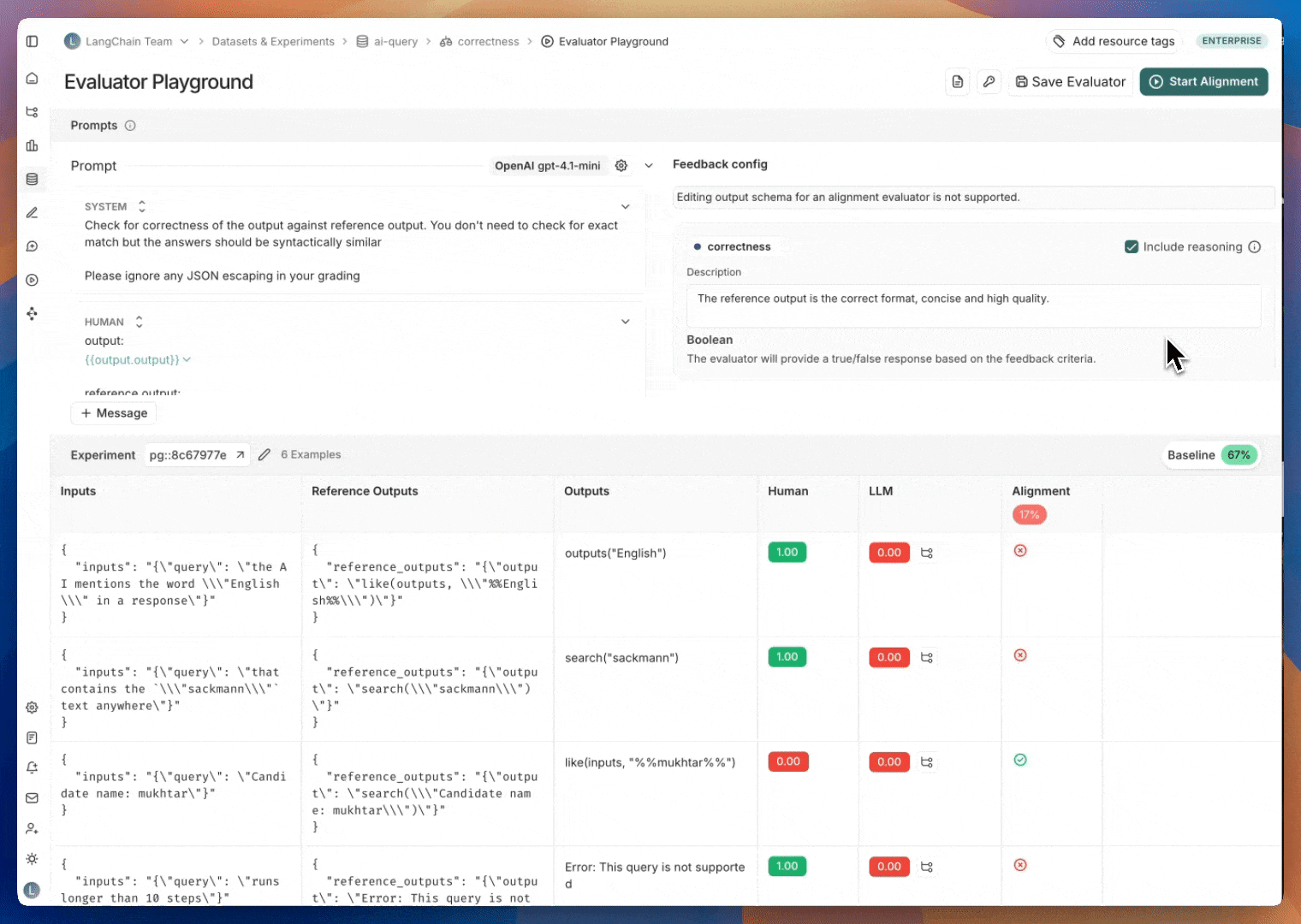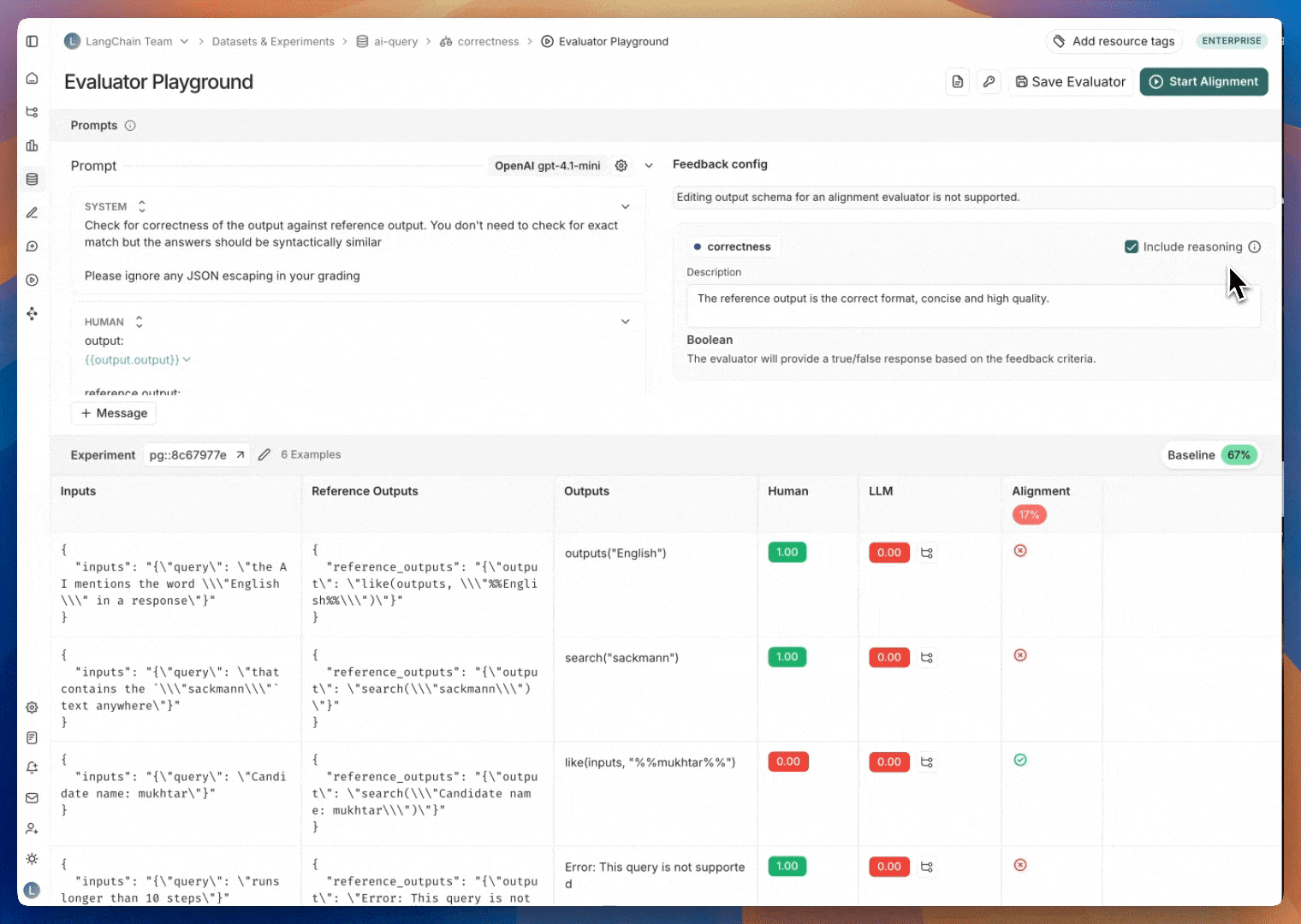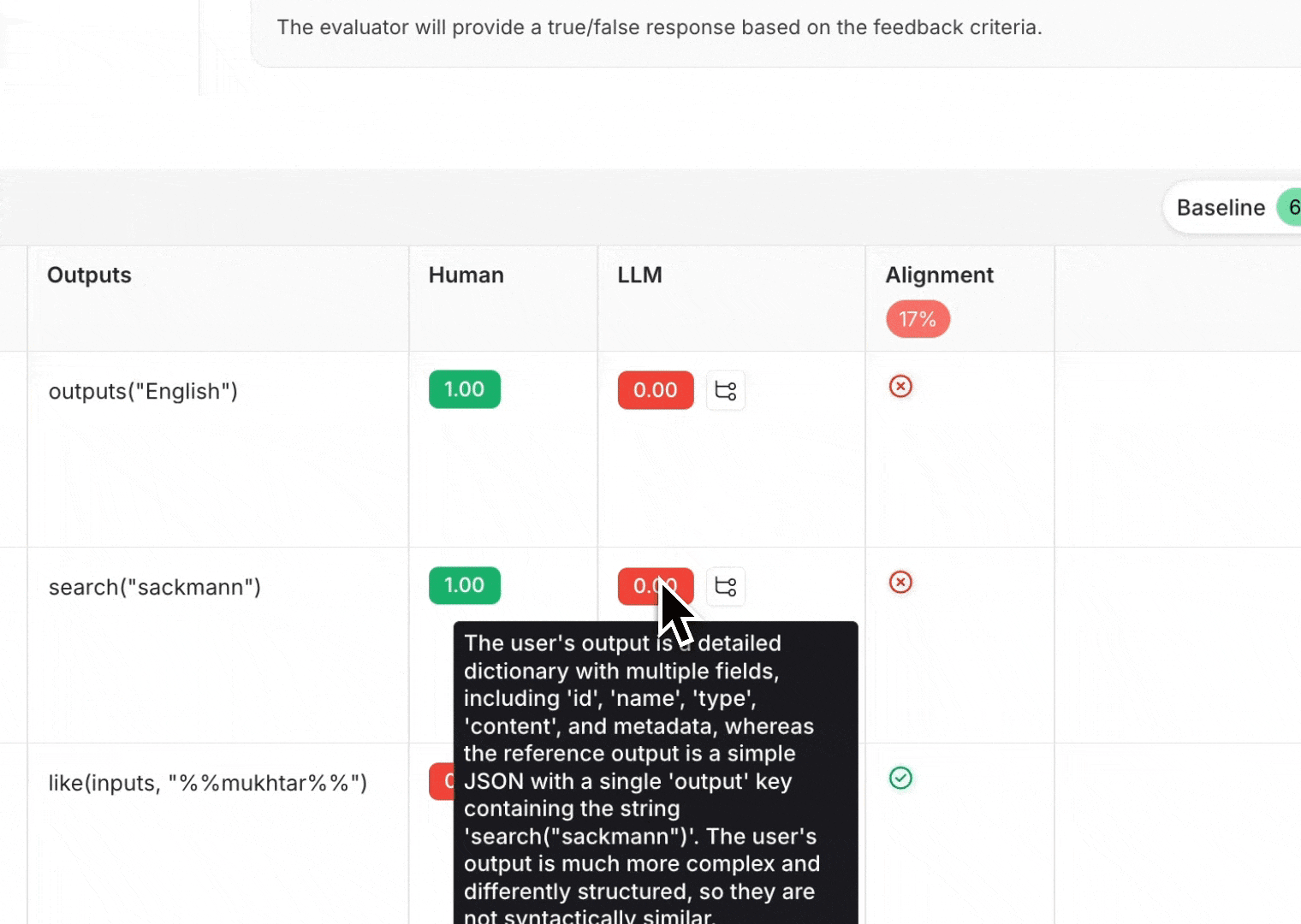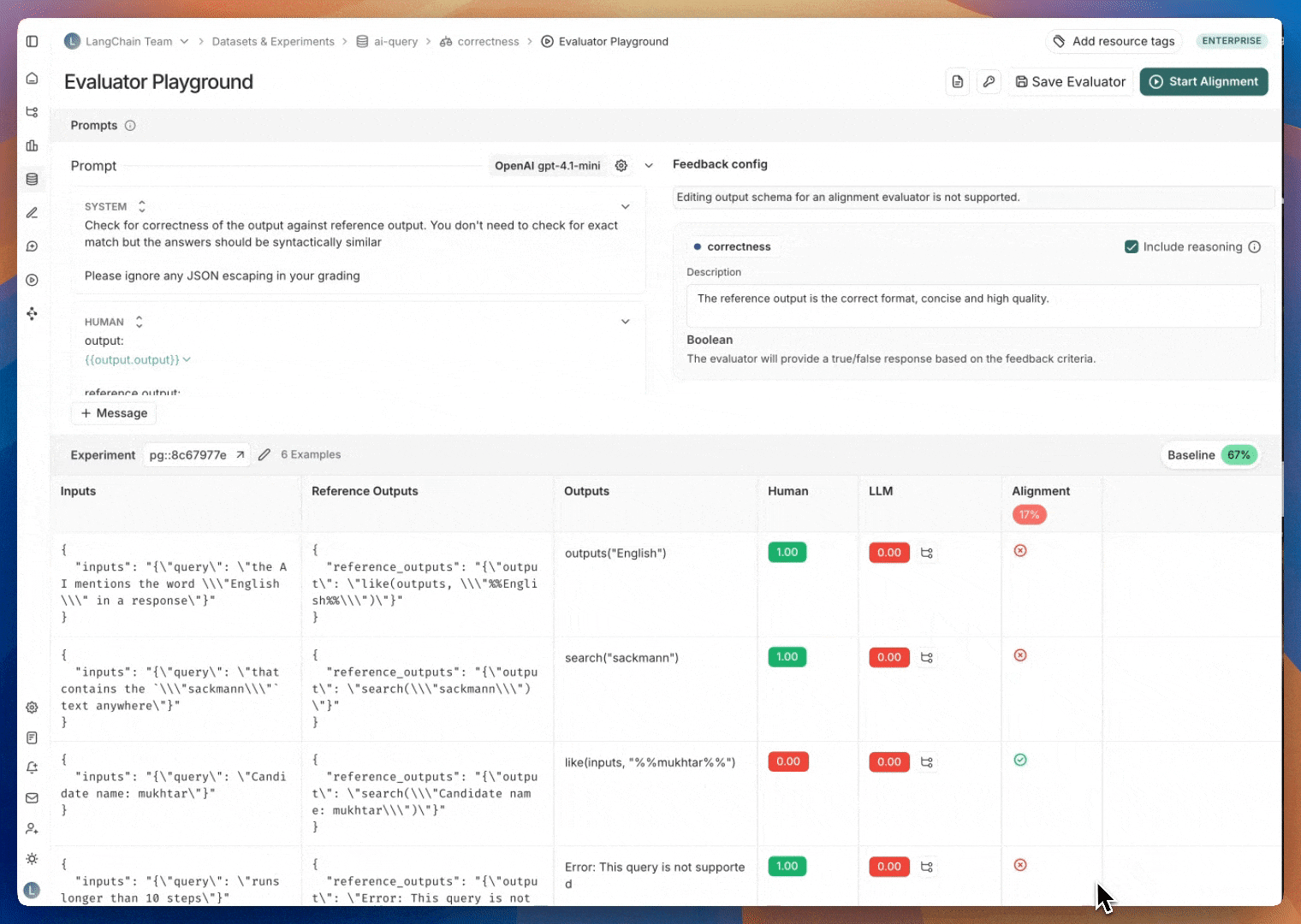
1. 정렬되지 않은 예제 조사 정렬되지 않은 예제를 파헤쳐서 공통적인 실패 모드로 그룹화하는 것은 평가자 정렬을 개선하기 위한 훌륭한 첫 단계입니다. 공통적인 실패 모드를 식별한 후 LLM이 이를 인식할 수 있도록 평가자 프롬프트에 지침을 추가합니다. 예를 들어, 특정 약어를 이해하지 못하는 것을 발견한 경우 “MFA는 ‘다단계 인증(multi-factor authentication)‘을 의미합니다”라고 설명할 수 있습니다. 또는 평가자의 맥락에서 좋음/나쁨이 무엇을 의미하는지 혼란스러워하는 경우 “좋은 응답에는 항상 예약할 수 있는 호텔이 최소 3개 포함되어야 합니다”라고 알려줄 수 있습니다. 2. LLM 점수의 근거 검토 LLM이 예제를 특정 방식으로 평가한 이유를 이해하려면 LLM-as-a-judge 평가자에 대한 추론을 활성화할 수 있습니다. 추론은 LLM의 사고 과정을 이해하는 데 도움이 되며, 평가자 프롬프트에 통합할 공통적인 실패 모드를 식별하는 데도 도움이 될 수 있습니다. 평가자 플레이그라운드에서 추론을 보려면 LLM 점수 위에 마우스를 올립니다.