

- 테스트 데이터셋 생성 방법
- 데이터셋에서 RAG 애플리케이션 실행 방법
- 다양한 평가 지표를 사용하여 애플리케이션 성능 측정 방법
개요
일반적인 RAG 평가 워크플로우는 세 가지 주요 단계로 구성됩니다:- 질문과 예상 답변이 포함된 데이터셋 생성
- 해당 질문에 대해 RAG 애플리케이션 실행
-
평가자를 사용하여 애플리케이션이 얼마나 잘 수행되었는지 측정하며, 다음과 같은 요소를 살펴봅니다:
- 답변 관련성
- 답변 정확도
- 검색 품질
설정
환경
먼저 환경 변수를 설정하겠습니다:Copy
import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = "YOUR LANGSMITH API KEY"
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI API KEY"
Copy
pip install -U langsmith langchain[openai] langchain-community
애플리케이션
이 튜토리얼에서는 LangChain을 사용하지만, 여기서 시연하는 평가 기법과 LangSmith 기능은 모든 프레임워크에서 작동합니다. 원하시는 도구와 라이브러리를 자유롭게 사용하세요.
- 인덱싱: Lilian Weng의 블로그 몇 개를 벡터 스토어에 청크로 나누고 인덱싱
- 검색: 사용자 질문을 기반으로 해당 청크 검색
- 생성: 질문과 검색된 문서를 LLM에 전달
인덱싱 및 검색
먼저 챗봇을 구축할 블로그 게시물을 로드하고 인덱싱하겠습니다.Copy
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# List of URLs to load documents from
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)
# Add the document chunks to the "vector store" using OpenAIEmbeddings
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
)
# With langchain we can easily turn any vector store into a retrieval component:
retriever = vectorstore.as_retriever(k=6)
생성
이제 생성 파이프라인을 정의할 수 있습니다.Copy
from langchain_openai import ChatOpenAI
from langsmith import traceable
llm = ChatOpenAI(model="gpt-4o", temperature=1)
# Add decorator so this function is traced in LangSmith
@traceable()
def rag_bot(question: str) -> dict:
# LangChain retriever will be automatically traced
docs = retriever.invoke(question)
docs_string = "".join(doc.page_content for doc in docs)
instructions = f"""You are a helpful assistant who is good at analyzing source information and answering questions.
Use the following source documents to answer the user's questions.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Documents:
{docs_string}"""
# langchain ChatModel will be automatically traced
ai_msg = llm.invoke([
{"role": "system", "content": instructions},
{"role": "user", "content": question},
],
)
return {"answer": ai_msg.content, "documents": docs}
데이터셋
이제 애플리케이션이 준비되었으니 이를 평가할 데이터셋을 구축하겠습니다. 이 경우 데이터셋은 매우 간단합니다: 예제 질문과 참조 답변을 가지게 됩니다.Copy
from langsmith import Client
client = Client()
# Define the examples for the dataset
examples = [
{
"inputs": {"question": "How does the ReAct agent use self-reflection? "},
"outputs": {"answer": "ReAct integrates reasoning and acting, performing actions - such tools like Wikipedia search API - and then observing / reasoning about the tool outputs."},
},
{
"inputs": {"question": "What are the types of biases that can arise with few-shot prompting?"},
"outputs": {"answer": "The biases that can arise with few-shot prompting include (1) Majority label bias, (2) Recency bias, and (3) Common token bias."},
},
{
"inputs": {"question": "What are five types of adversarial attacks?"},
"outputs": {"answer": "Five types of adversarial attacks are (1) Token manipulation, (2) Gradient based attack, (3) Jailbreak prompting, (4) Human red-teaming, (5) Model red-teaming."},
},
]
# Create the dataset and examples in LangSmith
dataset_name = "Lilian Weng Blogs Q&A"
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
평가자
다양한 유형의 RAG 평가자를 생각하는 한 가지 방법은 무엇을 평가하는지 X 무엇과 비교하여 평가하는지의 튜플로 생각하는 것입니다:- 정확성: 응답 vs 참조 답변
목표: “RAG 체인 답변이 정답(ground-truth answer)과 비교하여 얼마나 유사한지/올바른지” 측정모드: 데이터셋을 통해 제공되는 정답(참조) 답변이 필요평가자: LLM-as-judge를 사용하여 답변 정확성 평가
- 관련성: 응답 vs 입력
목표: “생성된 응답이 초기 사용자 입력을 얼마나 잘 다루는지” 측정모드: 답변을 입력 질문과 비교하므로 참조 답변이 필요하지 않음평가자: LLM-as-judge를 사용하여 답변 관련성, 유용성 등을 평가
- 근거성: 응답 vs 검색된 문서
목표: “생성된 응답이 검색된 컨텍스트와 얼마나 일치하는지” 측정모드: 답변을 검색된 컨텍스트와 비교하므로 참조 답변이 필요하지 않음평가자: LLM-as-judge를 사용하여 충실도, 환각 등을 평가
- 검색 관련성: 검색된 문서 vs 입력
목표: “이 쿼리에 대해 검색된 결과가 얼마나 관련성이 있는지” 측정모드: 질문을 검색된 컨텍스트와 비교하므로 참조 답변이 필요하지 않음평가자: LLM-as-judge를 사용하여 관련성 평가
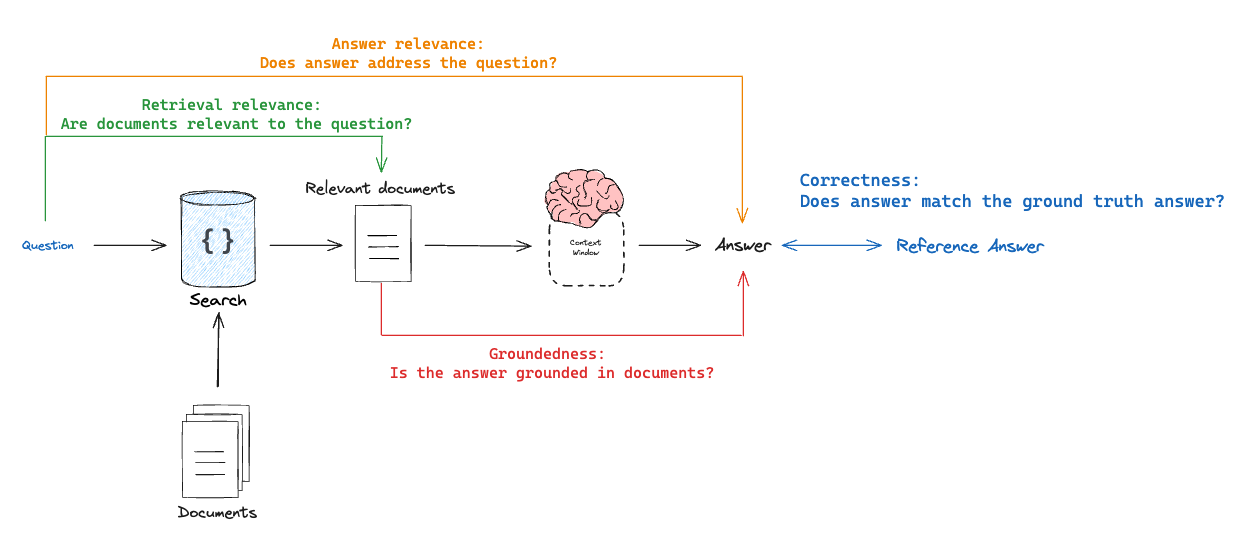
정확성: 응답 vs 참조 답변
Copy
from typing_extensions import Annotated, TypedDict
# Grade output schema
class CorrectnessGrade(TypedDict):
# Note that the order in the fields are defined is the order in which the model will generate them.
# It is useful to put explanations before responses because it forces the model to think through
# its final response before generating it:
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
correct: Annotated[bool, ..., "True if the answer is correct, False otherwise."]
# Grade prompt
correctness_instructions = """You are a teacher grading a quiz. You will be given a QUESTION, the GROUND TRUTH (correct) ANSWER, and the STUDENT ANSWER. Here is the grade criteria to follow:
(1) Grade the student answers based ONLY on their factual accuracy relative to the ground truth answer. (2) Ensure that the student answer does not contain any conflicting statements.
(3) It is OK if the student answer contains more information than the ground truth answer, as long as it is factually accurate relative to the ground truth answer.
Correctness:
A correctness value of True means that the student's answer meets all of the criteria.
A correctness value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grader_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
CorrectnessGrade, method="json_schema", strict=True
)
def correctness(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
"""An evaluator for RAG answer accuracy"""
answers = f"""\
QUESTION: {inputs['question']}
GROUND TRUTH ANSWER: {reference_outputs['answer']}
STUDENT ANSWER: {outputs['answer']}"""
# Run evaluator
grade = grader_llm.invoke([
{"role": "system", "content": correctness_instructions},
{"role": "user", "content": answers}
])
return grade["correct"]
관련성: 응답 vs 입력
흐름은 위와 유사하지만,reference_outputs 없이 inputs와 outputs만 살펴봅니다. 참조 답변이 없으면 정확도를 평가할 수 없지만, 관련성은 여전히 평가할 수 있습니다—즉, 모델이 사용자의 질문을 다루었는지 여부를 평가할 수 있습니다.
Copy
# Grade output schema
class RelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool, ..., "Provide the score on whether the answer addresses the question"
]
# Grade prompt
relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is concise and relevant to the QUESTION
(2) Ensure the STUDENT ANSWER helps to answer the QUESTION
Relevance:
A relevance value of True means that the student's answer meets all of the criteria.
A relevance value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
relevance_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
RelevanceGrade, method="json_schema", strict=True
)
# Evaluator
def relevance(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer helpfulness."""
answer = f"QUESTION: {inputs['question']}\nSTUDENT ANSWER: {outputs['answer']}"
grade = relevance_llm.invoke([
{"role": "system", "content": relevance_instructions},
{"role": "user", "content": answer}
])
return grade["relevant"]
근거성: 응답 vs 검색된 문서
참조 답변 없이 응답을 평가하는 또 다른 유용한 방법은 응답이 검색된 문서에 의해 정당화되는지(또는 “근거가 있는지”) 확인하는 것입니다.Copy
# Grade output schema
class GroundedGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
grounded: Annotated[
bool, ..., "Provide the score on if the answer hallucinates from the documents"
]
# Grade prompt
grounded_instructions = """You are a teacher grading a quiz. You will be given FACTS and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is grounded in the FACTS. (2) Ensure the STUDENT ANSWER does not contain "hallucinated" information outside the scope of the FACTS.
Grounded:
A grounded value of True means that the student's answer meets all of the criteria.
A grounded value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grounded_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
GroundedGrade, method="json_schema", strict=True
)
# Evaluator
def groundedness(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer groundedness."""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nSTUDENT ANSWER: {outputs['answer']}"
grade = grounded_llm.invoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": answer}
])
return grade["grounded"]
검색 관련성: 검색된 문서 vs 입력
Copy
# Grade output schema
class RetrievalRelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool,
...,
"True if the retrieved documents are relevant to the question, False otherwise",
]
# Grade prompt
retrieval_relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a set of FACTS provided by the student. Here is the grade criteria to follow:
(1) You goal is to identify FACTS that are completely unrelated to the QUESTION
(2) If the facts contain ANY keywords or semantic meaning related to the question, consider them relevant
(3) It is OK if the facts have SOME information that is unrelated to the question as long as (2) is met
Relevance:
A relevance value of True means that the FACTS contain ANY keywords or semantic meaning related to the QUESTION and are therefore relevant.
A relevance value of False means that the FACTS are completely unrelated to the QUESTION.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
retrieval_relevance_llm = ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(RetrievalRelevanceGrade, method="json_schema", strict=True)
def retrieval_relevance(inputs: dict, outputs: dict) -> bool:
"""An evaluator for document relevance"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nQUESTION: {inputs['question']}"
# Run evaluator
grade = retrieval_relevance_llm.invoke([
{"role": "system", "content": retrieval_relevance_instructions},
{"role": "user", "content": answer}
])
return grade["relevant"]
평가 실행
이제 모든 다양한 평가자를 사용하여 평가 작업을 시작할 수 있습니다.Copy
def target(inputs: dict) -> dict:
return rag_bot(inputs["question"])
experiment_results = client.evaluate(
target,
data=dataset_name,
evaluators=[correctness, groundedness, relevance, retrieval_relevance],
experiment_prefix="rag-doc-relevance",
metadata={"version": "LCEL context, gpt-4-0125-preview"},
)
# Explore results locally as a dataframe if you have pandas installed
# experiment_results.to_pandas()
참조 코드
위의 모든 코드를 통합한 스크립트입니다:
위의 모든 코드를 통합한 스크립트입니다:
Copy
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langsmith import Client, traceable
from typing_extensions import Annotated, TypedDict
# List of URLs to load documents from
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)
# Add the document chunks to the "vector store" using OpenAIEmbeddings
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
)
# With langchain we can easily turn any vector store into a retrieval component:
retriever = vectorstore.as_retriever(k=6)
llm = ChatOpenAI(model="gpt-4o", temperature=1)
# Add decorator so this function is traced in LangSmith
@traceable()
def rag_bot(question: str) -> dict:
# langchain Retriever will be automatically traced
docs = retriever.invoke(question)
docs_string = "".join(doc.page_content for doc in docs)
instructions = f"""You are a helpful assistant who is good at analyzing source information and answering questions.
Use the following source documents to answer the user's questions.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Documents:
{docs_string}"""
# langchain ChatModel will be automatically traced
ai_msg = llm.invoke([
{"role": "system", "content": instructions},
{"role": "user", "content": question},
],
)
return {"answer": ai_msg.content, "documents": docs}
client = Client()
# Define the examples for the dataset
examples = [
{
"inputs": {"question": "How does the ReAct agent use self-reflection? "},
"outputs": {"answer": "ReAct integrates reasoning and acting, performing actions - such tools like Wikipedia search API - and then observing / reasoning about the tool outputs."},
},
{
"inputs": {"question": "What are the types of biases that can arise with few-shot prompting?"},
"outputs": {"answer": "The biases that can arise with few-shot prompting include (1) Majority label bias, (2) Recency bias, and (3) Common token bias."},
},
{
"inputs": {"question": "What are five types of adversarial attacks?"},
"outputs": {"answer": "Five types of adversarial attacks are (1) Token manipulation, (2) Gradient based attack, (3) Jailbreak prompting, (4) Human red-teaming, (5) Model red-teaming."},
},
]
# Create the dataset and examples in LangSmith
dataset_name = "Lilian Weng Blogs Q&A"
if not client.has_dataset(dataset_name=dataset_name):
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
# Grade output schema
class CorrectnessGrade(TypedDict):
# Note that the order in the fields are defined is the order in which the model will generate them.
# It is useful to put explanations before responses because it forces the model to think through
# its final response before generating it:
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
correct: Annotated[bool, ..., "True if the answer is correct, False otherwise."]
# Grade prompt
correctness_instructions = """You are a teacher grading a quiz. You will be given a QUESTION, the GROUND TRUTH (correct) ANSWER, and the STUDENT ANSWER. Here is the grade criteria to follow:
(1) Grade the student answers based ONLY on their factual accuracy relative to the ground truth answer. (2) Ensure that the student answer does not contain any conflicting statements.
(3) It is OK if the student answer contains more information than the ground truth answer, as long as it is factually accurate relative to the ground truth answer.
Correctness:
A correctness value of True means that the student's answer meets all of the criteria.
A correctness value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grader_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
CorrectnessGrade, method="json_schema", strict=True
)
def correctness(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
"""An evaluator for RAG answer accuracy"""
answers = f"""\
QUESTION: {inputs['question']}
GROUND TRUTH ANSWER: {reference_outputs['answer']}
STUDENT ANSWER: {outputs['answer']}"""
# Run evaluator
grade = grader_llm.invoke([
{"role": "system", "content": correctness_instructions},
{"role": "user", "content": answers},
]
)
return grade["correct"]
# Grade output schema
class RelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool, ..., "Provide the score on whether the answer addresses the question"
]
# Grade prompt
relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is concise and relevant to the QUESTION
(2) Ensure the STUDENT ANSWER helps to answer the QUESTION
Relevance:
A relevance value of True means that the student's answer meets all of the criteria.
A relevance value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
relevance_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
RelevanceGrade, method="json_schema", strict=True
)
# Evaluator
def relevance(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer helpfulness."""
answer = f"QUESTION: {inputs['question']}\nSTUDENT ANSWER: {outputs['answer']}"
grade = relevance_llm.invoke([
{"role": "system", "content": relevance_instructions},
{"role": "user", "content": answer},
]
)
return grade["relevant"]
# Grade output schema
class GroundedGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
grounded: Annotated[
bool, ..., "Provide the score on if the answer hallucinates from the documents"
]
# Grade prompt
grounded_instructions = """You are a teacher grading a quiz. You will be given FACTS and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is grounded in the FACTS. (2) Ensure the STUDENT ANSWER does not contain "hallucinated" information outside the scope of the FACTS.
Grounded:
A grounded value of True means that the student's answer meets all of the criteria.
A grounded value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grounded_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
GroundedGrade, method="json_schema", strict=True
)
# Evaluator
def groundedness(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer groundedness."""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nSTUDENT ANSWER: {outputs['answer']}"
grade = grounded_llm.invoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": answer},
]
)
return grade["grounded"]
# Grade output schema
class RetrievalRelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool,
...,
"True if the retrieved documents are relevant to the question, False otherwise",
]
# Grade prompt
retrieval_relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a set of FACTS provided by the student. Here is the grade criteria to follow:
(1) You goal is to identify FACTS that are completely unrelated to the QUESTION
(2) If the facts contain ANY keywords or semantic meaning related to the question, consider them relevant
(3) It is OK if the facts have SOME information that is unrelated to the question as long as (2) is met
Relevance:
A relevance value of True means that the FACTS contain ANY keywords or semantic meaning related to the QUESTION and are therefore relevant.
A relevance value of False means that the FACTS are completely unrelated to the QUESTION.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
retrieval_relevance_llm = ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(RetrievalRelevanceGrade, method="json_schema", strict=True)
def retrieval_relevance(inputs: dict, outputs: dict) -> bool:
"""An evaluator for document relevance"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nQUESTION: {inputs['question']}"
# Run evaluator
grade = retrieval_relevance_llm.invoke([
{"role": "system", "content": retrieval_relevance_instructions},
{"role": "user", "content": answer},
]
)
return grade["relevant"]
def target(inputs: dict) -> dict:
return rag_bot(inputs["question"])
experiment_results = client.evaluate(
target,
data=dataset_name,
evaluators=[correctness, groundedness, relevance, retrieval_relevance],
experiment_prefix="rag-doc-relevance",
metadata={"version": "LCEL context, gpt-4-0125-preview"},
)
# Explore results locally as a dataframe if you have pandas installed
# experiment_results.to_pandas()
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.