

- 성능 측정을 위한 초기 골든 데이터셋 생성
- 성능 측정에 사용할 메트릭 정의
- 여러 다른 프롬프트나 모델에 대한 평가 실행
- 결과를 수동으로 비교
- 시간 경과에 따른 결과 추적
- CI/CD에서 실행할 자동화된 테스트 설정
설정
먼저 이 튜토리얼에 필요한 종속성을 설치합니다. 여기서는 OpenAI를 사용하지만, LangSmith는 어떤 모델과도 함께 사용할 수 있습니다:데이터셋 생성
애플리케이션을 테스트하고 평가할 준비를 할 때 첫 번째 단계는 평가하려는 데이터 포인트를 정의하는 것입니다. 여기서 고려해야 할 몇 가지 측면이 있습니다:- 각 데이터 포인트의 스키마는 어떻게 되어야 하는가?
- 몇 개의 데이터 포인트를 수집해야 하는가?
- 데이터 포인트를 어떻게 수집해야 하는가?
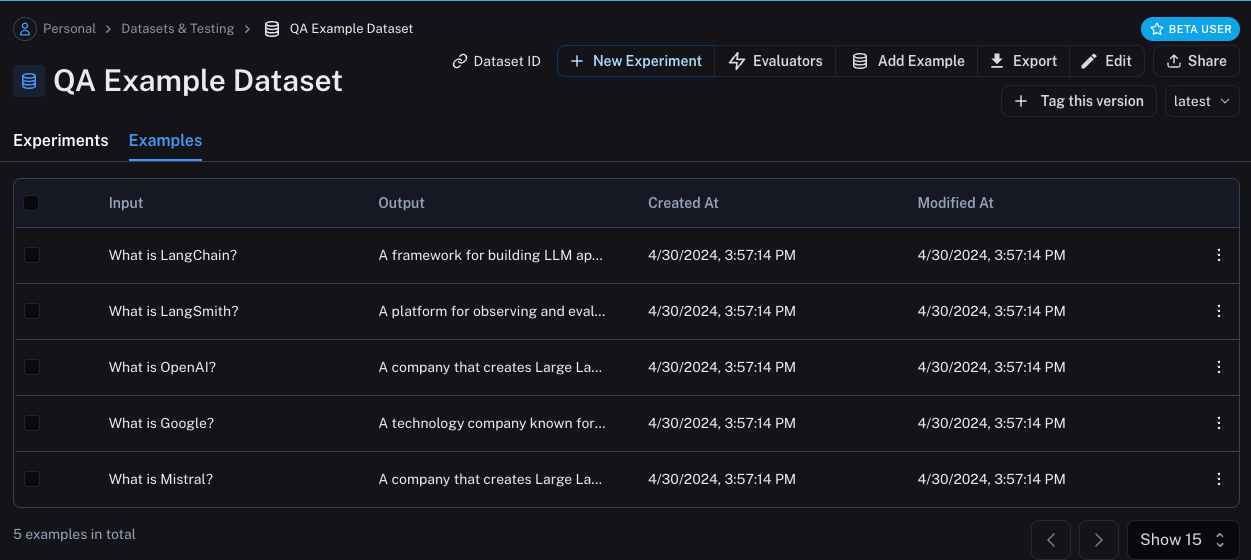
Datasets & Testing 페이지에서 QA Example Dataset을 찾아 클릭하면 5개의 새로운 예제가 있는 것을 볼 수 있습니다.
메트릭 정의
데이터셋을 생성한 후, 이제 응답을 평가할 몇 가지 메트릭을 정의할 수 있습니다. 예상 답변이 있으므로 평가의 일부로 이를 비교할 수 있습니다. 그러나 애플리케이션이 정확히 그 답변을 출력할 것으로 기대하지는 않고, 오히려 유사한 내용을 출력할 것으로 기대합니다. 이렇게 되면 평가가 조금 더 까다로워집니다. 정확성 평가 외에도 답변이 짧고 간결한지 확인해 보겠습니다. 이는 조금 더 쉬울 것입니다. 응답의 길이를 측정하는 간단한 Python 함수를 정의할 수 있습니다. 이 두 가지 메트릭을 정의해 보겠습니다. 첫 번째의 경우, LLM을 사용하여 출력이 (예상 출력과 비교하여) 올바른지 판단할 것입니다. 이러한 LLM-as-a-judge는 간단한 함수로 측정하기에는 너무 복잡한 경우에 비교적 일반적입니다. 여기에서 평가에 사용할 자체 프롬프트와 LLM을 정의할 수 있습니다:평가 실행
훌륭합니다! 그렇다면 이제 평가를 어떻게 실행할까요? 이제 데이터셋과 평가자가 있으니 필요한 것은 애플리케이션뿐입니다! 응답 방법에 대한 지침이 포함된 시스템 메시지를 가지고 있다가 LLM에 전달하는 간단한 애플리케이션을 구축하겠습니다. OpenAI SDK를 직접 사용하여 구축하겠습니다: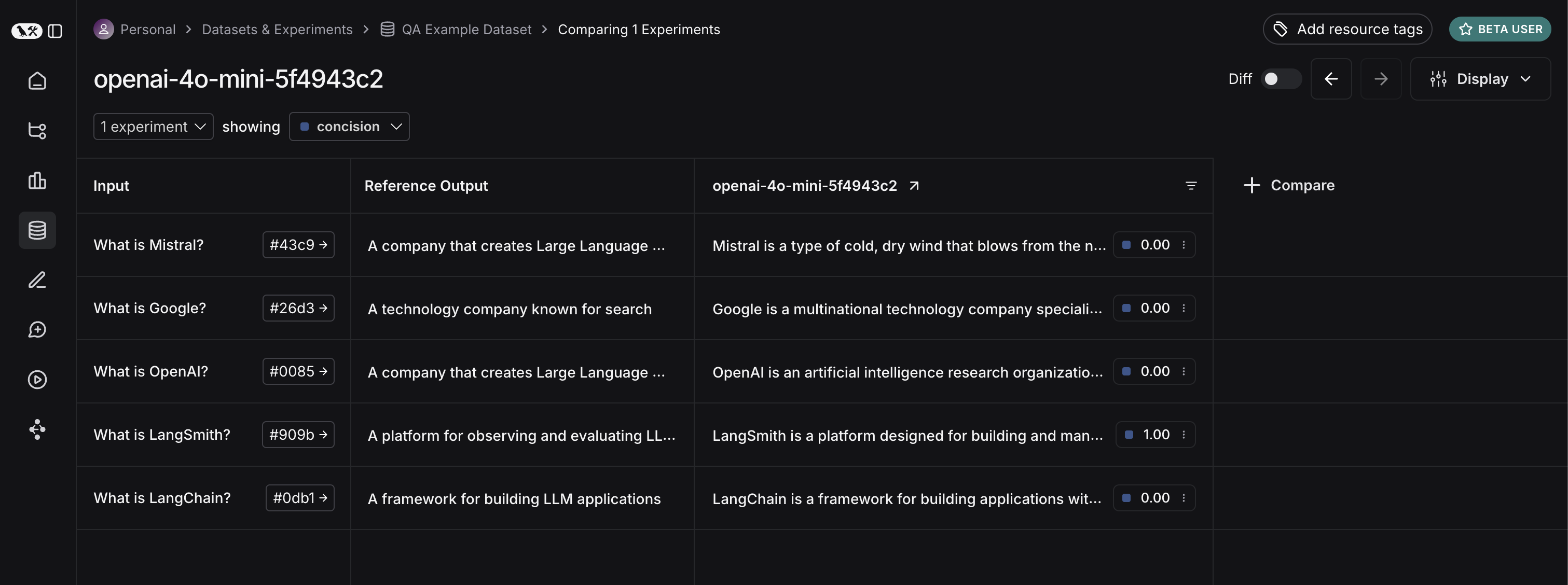
Experiments 탭을 선택하면 이제 하나의 실행 요약을 볼 수 있습니다!
gpt-4-turbo를 시도해 보겠습니다.
Experiments 탭으로 돌아가면 세 가지 실행이 모두 표시되는 것을 볼 수 있습니다!
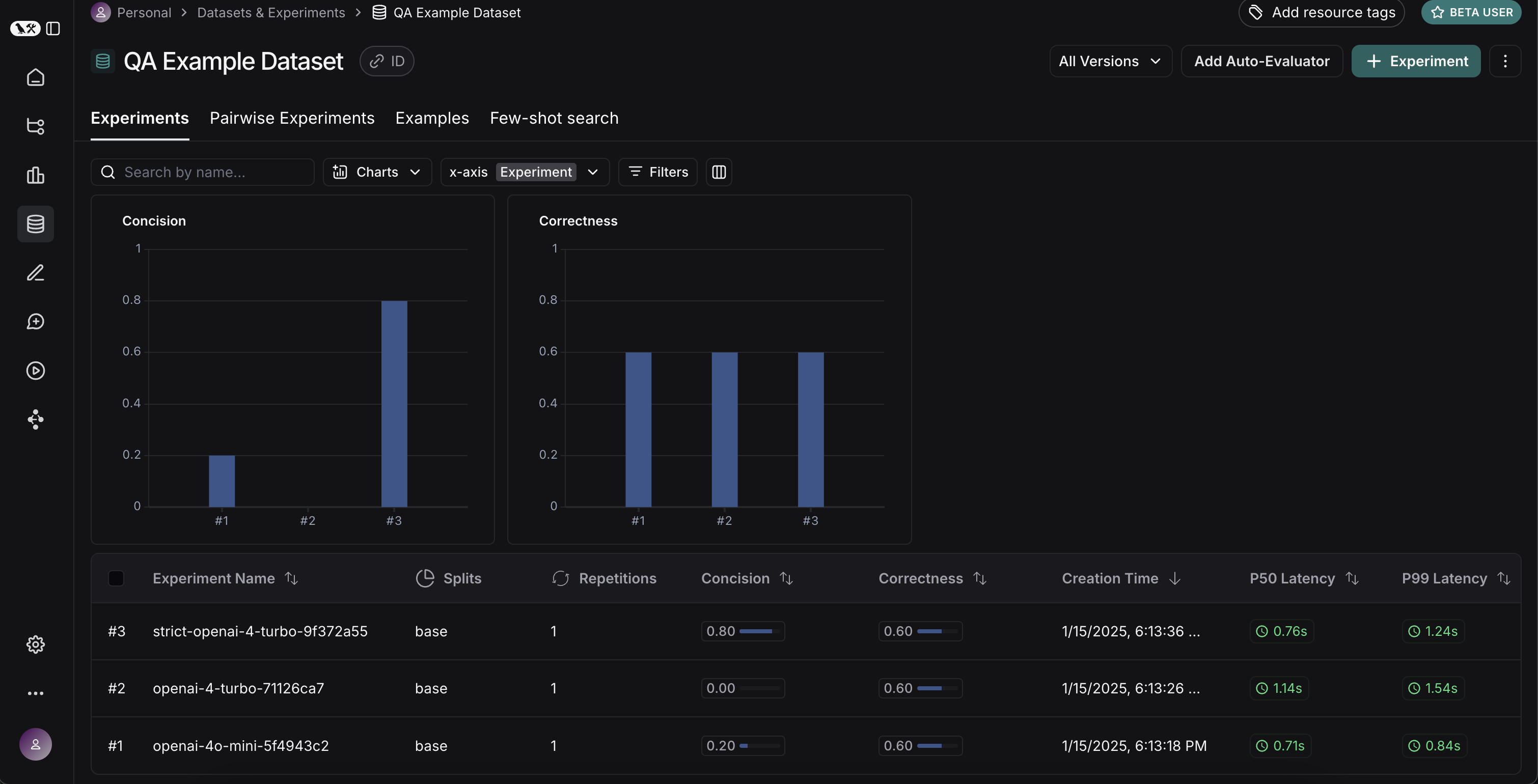
결과 비교
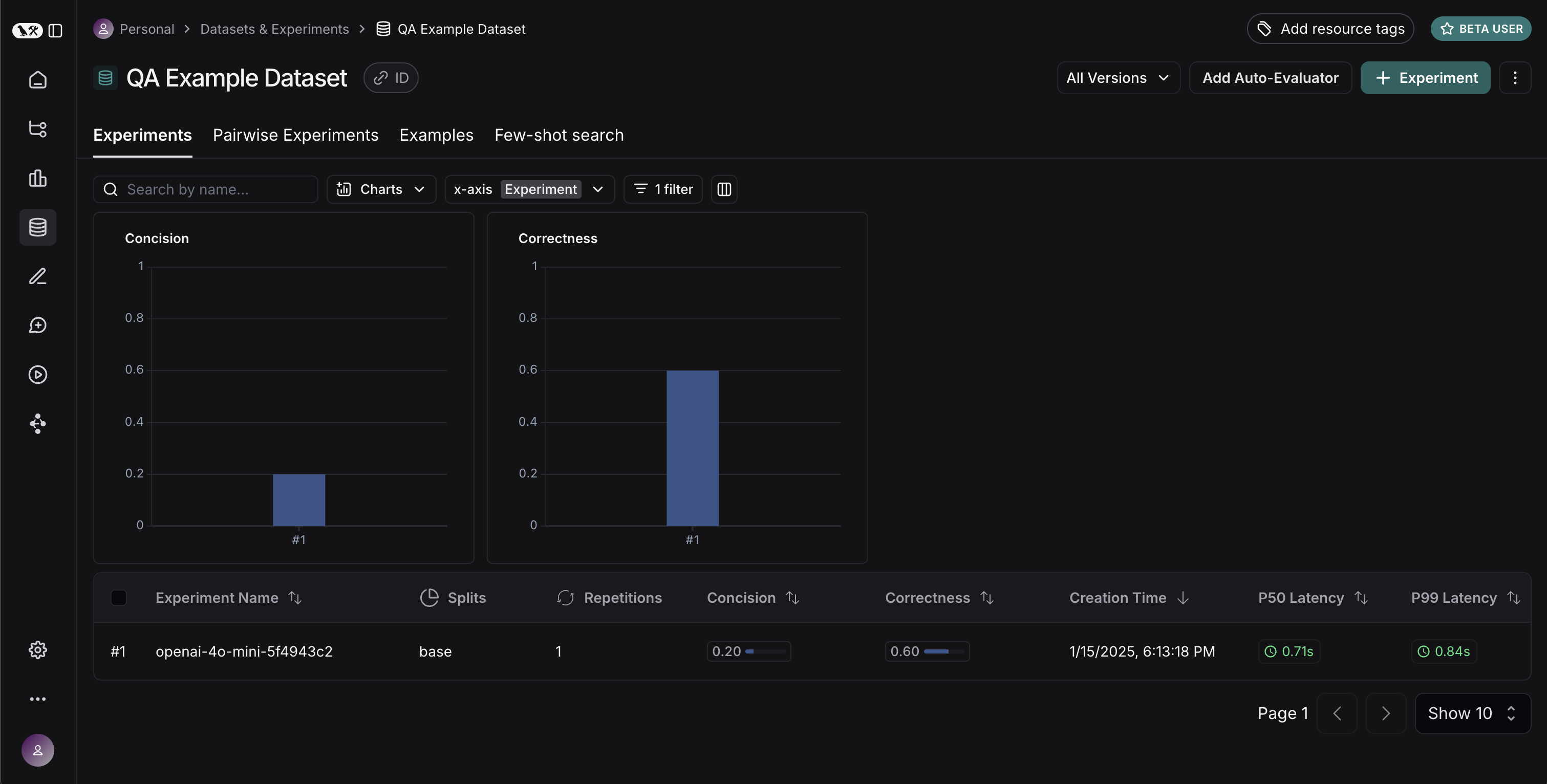
멋집니다, 세 가지 다른 실행을 평가했습니다. 하지만 결과를 어떻게 비교할 수 있을까요? 첫 번째 방법은Experiments 탭에서 실행을 살펴보는 것입니다. 그렇게 하면 각 실행에 대한 메트릭의 높은 수준 보기를 볼 수 있습니다:
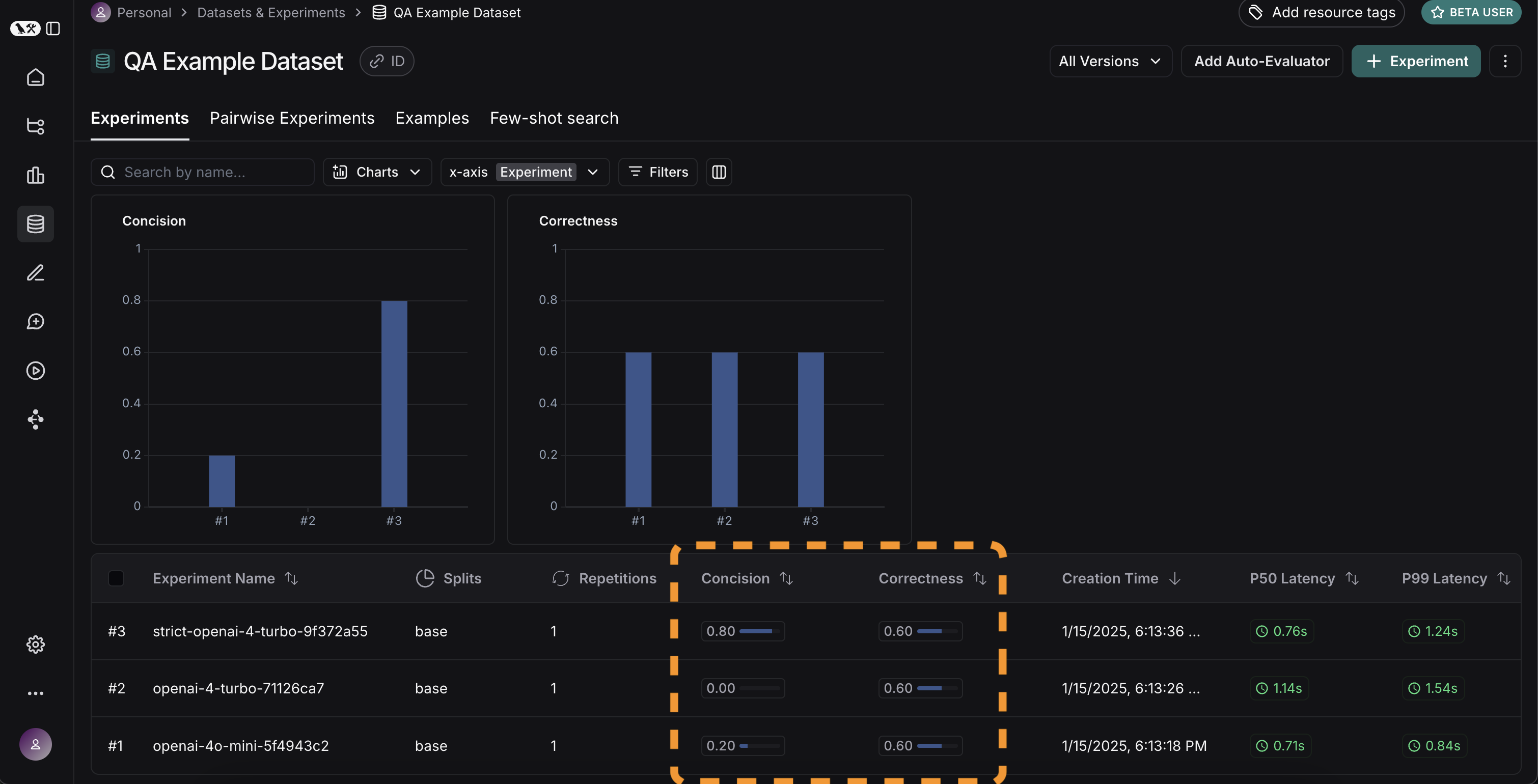
Display 컨트롤을 사용하여 어떤 열과 어떤 메트릭을 볼지 선택할 수도 있습니다. 상단의 아이콘을 클릭하여 개선/회귀가 있는 실행만 자동으로 필터링할 수도 있습니다.
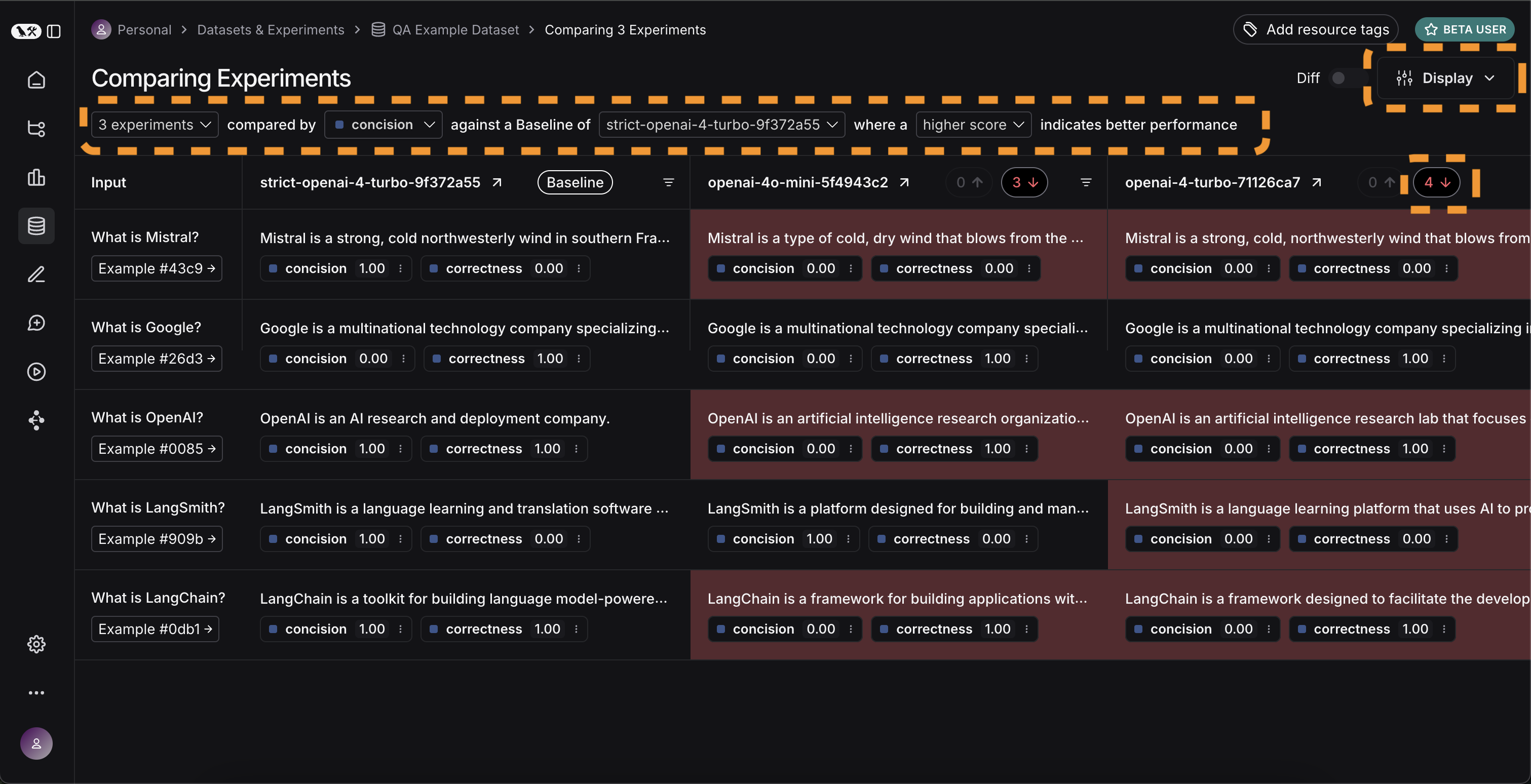
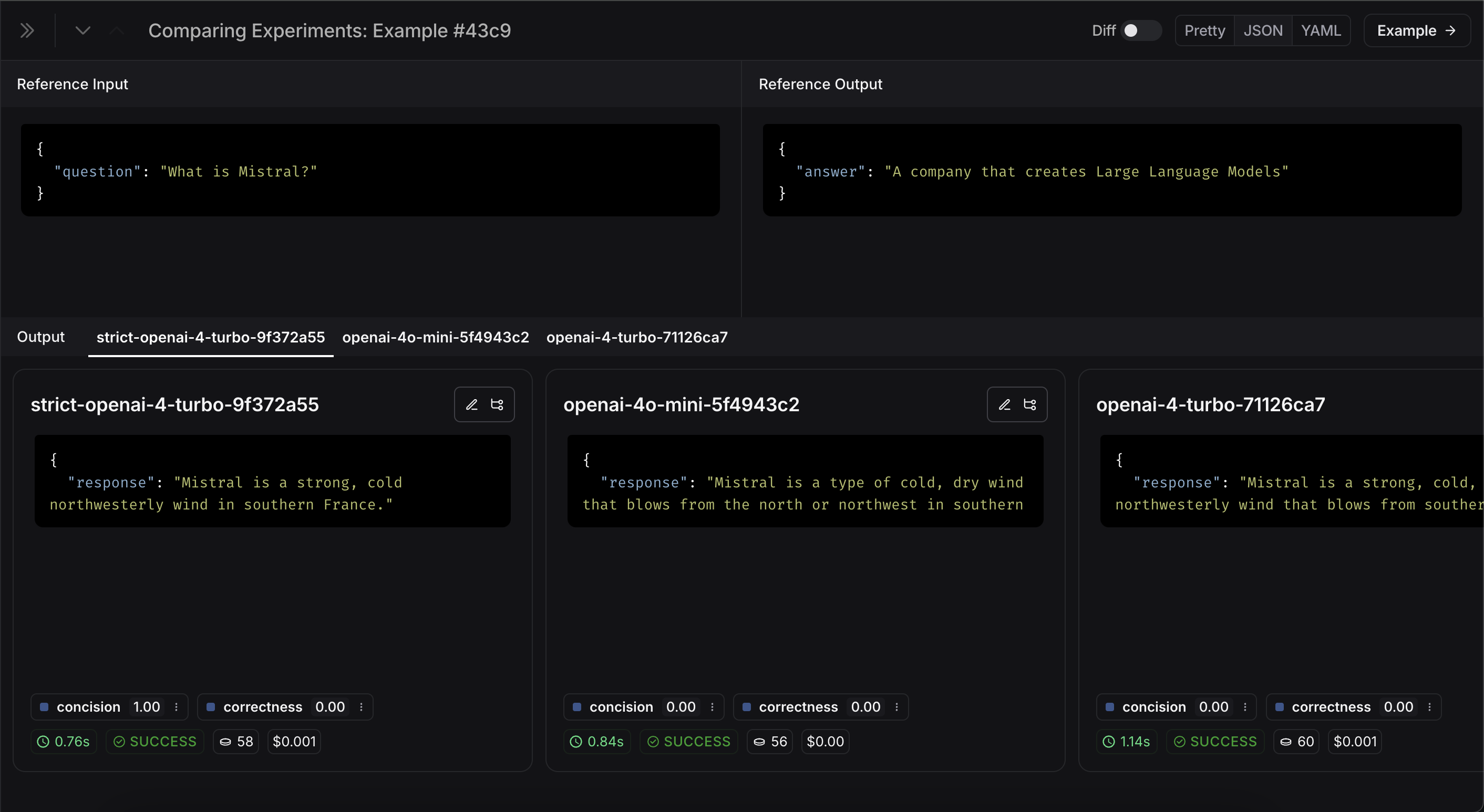
Expand 버튼을 선택하여 더 자세한 정보가 있는 사이드 패널을 열 수도 있습니다:
CI/CD에서 실행할 자동화된 테스트 설정
이제 일회성 방식으로 실행했으므로 자동화된 방식으로 실행하도록 설정할 수 있습니다. CI/CD에서 실행하는 pytest 파일로 포함하면 매우 쉽게 수행할 수 있습니다. 이의 일환으로 결과만 기록하거나 통과 여부를 결정하기 위한 일부 기준을 설정할 수 있습니다. 예를 들어, 생성된 응답의 최소 80%가 항상length 체크를 통과하도록 보장하려면 다음과 같은 테스트로 설정할 수 있습니다:
시간 경과에 따른 결과 추적
이제 이러한 실험이 자동화된 방식으로 실행되고 있으므로 시간 경과에 따라 이러한 결과를 추적하고 싶습니다. 데이터셋 페이지의 전체Experiments 탭에서 이를 수행할 수 있습니다. 기본적으로 시간 경과에 따른 평가 메트릭을 표시합니다(빨간색으로 강조 표시됨). 또한 코드 브랜치와 쉽게 연결할 수 있도록 git 메트릭을 자동으로 추적합니다(노란색으로 강조 표시됨).
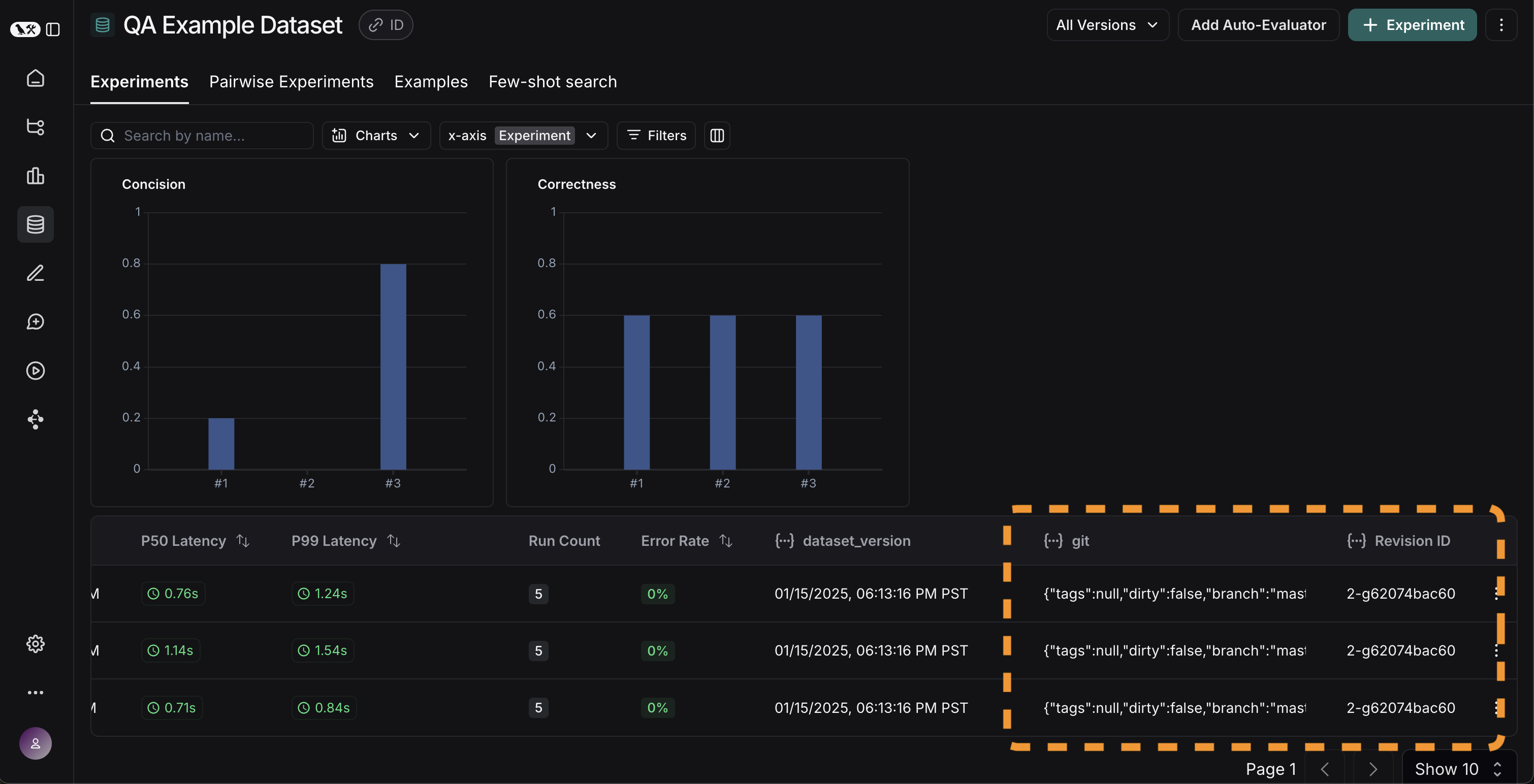
결론
이 튜토리얼은 여기까지입니다! 초기 테스트 세트를 생성하고, 일부 평가 메트릭을 정의하고, 실험을 실행하고, 수동으로 비교하고, CI/CD를 설정하고, 시간 경과에 따라 결과를 추적하는 방법을 살펴보았습니다. 이를 통해 확신을 가지고 반복 개선할 수 있기를 바랍니다. 이것은 시작에 불과합니다. 앞서 언급했듯이 평가는 지속적인 프로세스입니다. 예를 들어, 평가하려는 데이터 포인트는 시간이 지남에 따라 계속 변경될 가능성이 높습니다. 탐색하고 싶은 다양한 유형의 평가자가 있을 수 있습니다. 이에 대한 자세한 내용은 사용 방법 가이드를 확인하세요. 또한 이 “오프라인” 방식 외에 데이터를 평가하는 다른 방법이 있습니다(예: 프로덕션 데이터를 평가할 수 있습니다). 온라인 평가에 대한 자세한 내용은 이 가이드를 확인하세요.참조 코드
통합된 코드 스니펫을 보려면 클릭하세요
통합된 코드 스니펫을 보려면 클릭하세요