애플리케이션을 배포하는 것은 지속적인 개선 프로세스의 시작일 뿐입니다. 프로덕션 환경에 배포한 후에는 프롬프트, 언어 모델, 도구, 그리고 아키텍처를 개선하여 시스템을 더욱 정교하게 다듬어야 합니다. 백테스팅은 과거 데이터를 사용하여 애플리케이션의 새로운 버전을 평가하고, 새로운 출력 결과를 원본 결과와 비교하는 작업입니다. 프로덕션 이전 데이터셋을 사용한 평가와 비교할 때, 백테스팅은 새로운 버전의 애플리케이션이 현재 배포된 버전보다 개선되었는지 더 명확하게 보여줍니다.
백테스팅의 기본 단계는 다음과 같습니다:
- 프로덕션 트레이싱 프로젝트에서 테스트할 샘플 실행을 선택합니다.
- 실행 입력을 데이터셋으로 변환하고, 실행 출력을 해당 데이터셋에 대한 초기 실험으로 기록합니다.
- 새로운 시스템을 새 데이터셋에서 실행하고 실험 결과를 비교합니다.
이 프로세스를 통해 대표적인 입력으로 구성된 새로운 데이터셋을 얻을 수 있으며, 이를 버전 관리하고 모델의 백테스팅에 활용할 수 있습니다.
대부분의 경우 명확한 “정답(ground truth)“을 사용할 수 없습니다. 이런 경우에는 출력을 수동으로 레이블링하거나 참조 데이터가 필요하지 않은 평가자를 사용할 수 있습니다. 애플리케이션에서 정답 레이블을 수집할 수 있는 경우, 예를 들어 사용자가 피드백을 남길 수 있도록 하는 경우, 이를 적극 활용할 것을 권장합니다.
환경 구성
라이브러리를 설치하고 환경 변수를 설정합니다. 이 가이드는 langsmith>=0.2.4가 필요합니다.
편의를 위해 이 튜토리얼에서는 LangChain OSS 프레임워크를 사용하지만, 여기서 소개하는 LangSmith 기능은 프레임워크에 구애받지 않습니다.
pip install -U langsmith langchain langchain-anthropic langchainhub emoji
import getpass
import os
# 테스트할 프로젝트 이름을 설정합니다
project_name = "Tweet Writing Task"
os.environ["LANGSMITH_PROJECT"] = project_name
os.environ["LANGSMITH_TRACING"] = "true"
if not os.environ.get("LANGSMITH_API_KEY"):
os.environ["LANGSMITH_API_KEY"] = getpass.getpass("YOUR API KEY")
# 선택 사항. OpenAI를 다른 도구 호출 채팅 모델로 변경할 수 있습니다.
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI API KEY"
# 선택 사항. 원한다면 Tavily를 무료 DuckDuckGo 검색 도구로 변경할 수 있습니다.
# Tavily API 키 받기: https://tavily.com
os.environ["TAVILY_API_KEY"] = "YOUR TAVILY API KEY"
애플리케이션 정의
이 예제에서는 인터넷 검색 도구에 접근할 수 있는 간단한 트윗 작성 애플리케이션을 만들어 보겠습니다:
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langchain_community.tools import DuckDuckGoSearchRun, TavilySearchResults
from langchain_core.rate_limiters import InMemoryRateLimiter
# GPT-3.5 Turbo를 기준선으로 사용하고 GPT-4o와 비교할 것입니다
gpt_3_5_turbo = init_chat_model(
"gpt-3.5-turbo",
temperature=1,
configurable_fields=("model", "model_provider"),
)
# 지시사항은 시스템 메시지로 에이전트에 전달됩니다
instructions = """You are a tweet writing assistant. Given a topic, do some research and write a relevant and engaging tweet about it.
- Use at least 3 emojis in each tweet
- The tweet should be no longer than 280 characters
- Always use the search tool to gather recent information on the tweet topic
- Write the tweet only based on the search content. Do not rely on your internal knowledge
- When relevant, link to your sources
- Make your tweet as engaging as possible"""
# 에이전트가 사용할 도구를 정의합니다
# 더 높은 등급의 Tavily API 플랜이 있다면 이 값을 늘릴 수 있습니다
rate_limiter = InMemoryRateLimiter(requests_per_second=0.08)
# Tavily API 키가 없다면 DuckDuckGo를 사용하세요:
# tools = [DuckDuckGoSearchRun(rate_limiter=rate_limiter)]
tools = [TavilySearchResults(max_results=5, rate_limiter=rate_limiter)]
agent = create_agent(gpt_3_5_turbo, tools=tools, system_prompt=instructions)
프로덕션 데이터 시뮬레이션
이제 프로덕션 데이터를 시뮬레이션해 보겠습니다:
fake_production_inputs = [
"Alan turing's early childhood",
"Economic impacts of the European Union",
"Underrated philosophers",
"History of the Roxie theater in San Francisco",
"ELI5: gravitational waves",
"The arguments for and against a parliamentary system",
"Pivotal moments in music history",
"Big ideas in programming languages",
"Big questions in biology",
"The relationship between math and reality",
"What makes someone funny",
]
agent.batch(
[{"messages": [{"role": "user", "content": content}]} for content in fake_production_inputs],
)
프로덕션 트레이스를 실험으로 변환
첫 번째 단계는 프로덕션 입력을 기반으로 데이터셋을 생성하는 것입니다. 그런 다음 모든 트레이스를 복사하여 기준선 실험으로 사용합니다.
백테스트할 실행 선택
list_runs의 filter 인수를 사용하여 백테스트할 실행을 선택할 수 있습니다. filter 인수는 LangSmith 트레이스 쿼리 구문을 사용하여 실행을 선택합니다.
from datetime import datetime, timedelta, timezone
from uuid import uuid4
from langsmith import Client
from langsmith.beta import convert_runs_to_test
# 데이터셋/실험으로 변환할 실행을 가져옵니다
client = Client()
# 데이터셋에 포함할 실행을 샘플링하는 방법
end_time = datetime.now(tz=timezone.utc)
start_time = end_time - timedelta(days=1)
run_filter = f'and(gt(start_time, "{start_time.isoformat()}"), lt(end_time, "{end_time.isoformat()}"))'
prod_runs = list(
client.list_runs(
project_name=project_name,
is_root=True,
filter=run_filter,
)
)
실행을 실험으로 변환
convert_runs_to_test는 일부 실행을 받아 다음 작업을 수행하는 함수입니다:
- 입력과 선택적으로 출력을 Example로 데이터셋에 저장합니다.
- 입력과 출력을 실험으로 저장하며, 이는
evaluate 함수를 실행하여 해당 출력을 받은 것처럼 처리됩니다.
# 생성할 데이터셋 이름
dataset_name = f'{project_name}-backtesting {start_time.strftime("%Y-%m-%d")}-{end_time.strftime("%Y-%m-%d")}'
# 과거 실행에서 생성할 실험 이름
baseline_experiment_name = f"prod-baseline-gpt-3.5-turbo-{str(uuid4())[:4]}"
# 실행을 데이터셋 + 실험으로 변환합니다
convert_runs_to_test(
prod_runs,
# 결과 데이터셋의 이름
dataset_name=dataset_name,
# 실행 출력을 참조/정답으로 포함할지 여부
include_outputs=False,
# 결과 실험에 전체 트레이스를 포함할지 여부
# (기본값은 루트 실행만 포함)
load_child_runs=True,
# 나중에 평가자를 적용할 수 있도록 실험 이름 지정
test_project_name=baseline_experiment_name
)
새로운 시스템과 벤치마크 비교
이제 프로덕션 실행을 새로운 시스템과 벤치마크하는 프로세스를 시작할 수 있습니다.
평가자 정의
먼저 두 시스템을 비교하는 데 사용할 평가자를 정의하겠습니다. 참조 출력이 없으므로 실제 출력만 필요한 평가 지표를 만들어야 합니다.
import emoji
from pydantic import BaseModel, Field
from langchain_core.messages import convert_to_openai_messages
class Grade(BaseModel):
"""응답이 컨텍스트에 의해 뒷받침되는지 평가합니다."""
grounded: bool = Field(..., description="Is the majority of the response supported by the retrieved context?")
grounded_instructions = f"""You have given somebody some contextual information and asked them to write a statement grounded in that context.
Grade whether their response is fully supported by the context you have provided. \
If any meaningful part of their statement is not backed up directly by the context you provided, then their response is not grounded. \
Otherwise it is grounded."""
grounded_model = init_chat_model(model="gpt-4o").with_structured_output(Grade)
def lt_280_chars(outputs: dict) -> bool:
messages = convert_to_openai_messages(outputs["messages"])
return len(messages[-1]['content']) <= 280
def gte_3_emojis(outputs: dict) -> bool:
messages = convert_to_openai_messages(outputs["messages"])
return len(emoji.emoji_list(messages[-1]['content'])) >= 3
async def is_grounded(outputs: dict) -> bool:
context = ""
messages = convert_to_openai_messages(outputs["messages"])
for message in messages:
if message["role"] == "tool":
# 도구 메시지 출력은 Tavily/DuckDuckGo 도구에서 반환된 결과입니다
context += "\n\n" + message["content"]
tweet = messages[-1]["content"]
user = f"""CONTEXT PROVIDED:
{context}
RESPONSE GIVEN:
{tweet}"""
grade = await grounded_model.ainvoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": user}
])
return grade.grounded
기준선 평가
이제 기준선 실험에 대해 평가자를 실행해 보겠습니다.
baseline_results = await client.aevaluate(
baseline_experiment_name,
evaluators=[lt_280_chars, gte_3_emojis, is_grounded],
)
# pandas가 설치되어 있다면 결과를 DataFrame으로 쉽게 탐색할 수 있습니다:
# baseline_results.to_pandas()
새로운 시스템 정의 및 평가
이제 새로운 시스템을 정의하고 평가해 보겠습니다. 이 예제에서는 새로운 시스템이 기존 시스템과 동일하지만 GPT-3.5 대신 GPT-4o를 사용합니다. 모델을 구성 가능하게 만들었으므로 에이전트에 전달되는 기본 구성만 업데이트하면 됩니다:
candidate_results = await client.aevaluate(
agent.with_config(model="gpt-4o"),
data=dataset_name,
evaluators=[lt_280_chars, gte_3_emojis, is_grounded],
experiment_prefix="candidate-gpt-4o",
)
# pandas가 설치되어 있다면 결과를 DataFrame으로 쉽게 탐색할 수 있습니다:
# candidate_results.to_pandas()
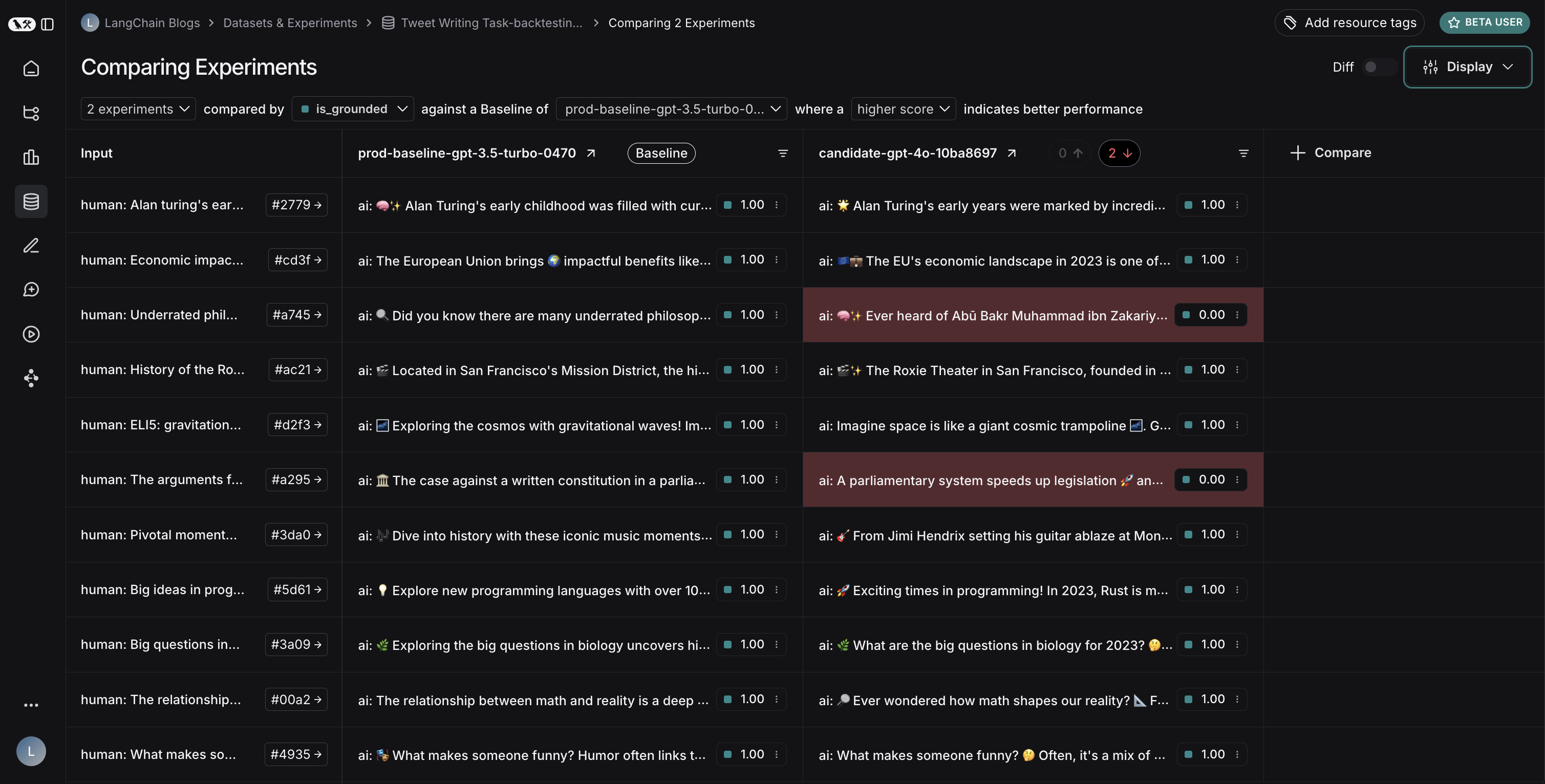
결과 비교
두 실험을 모두 실행한 후 데이터셋에서 결과를 확인할 수 있습니다:
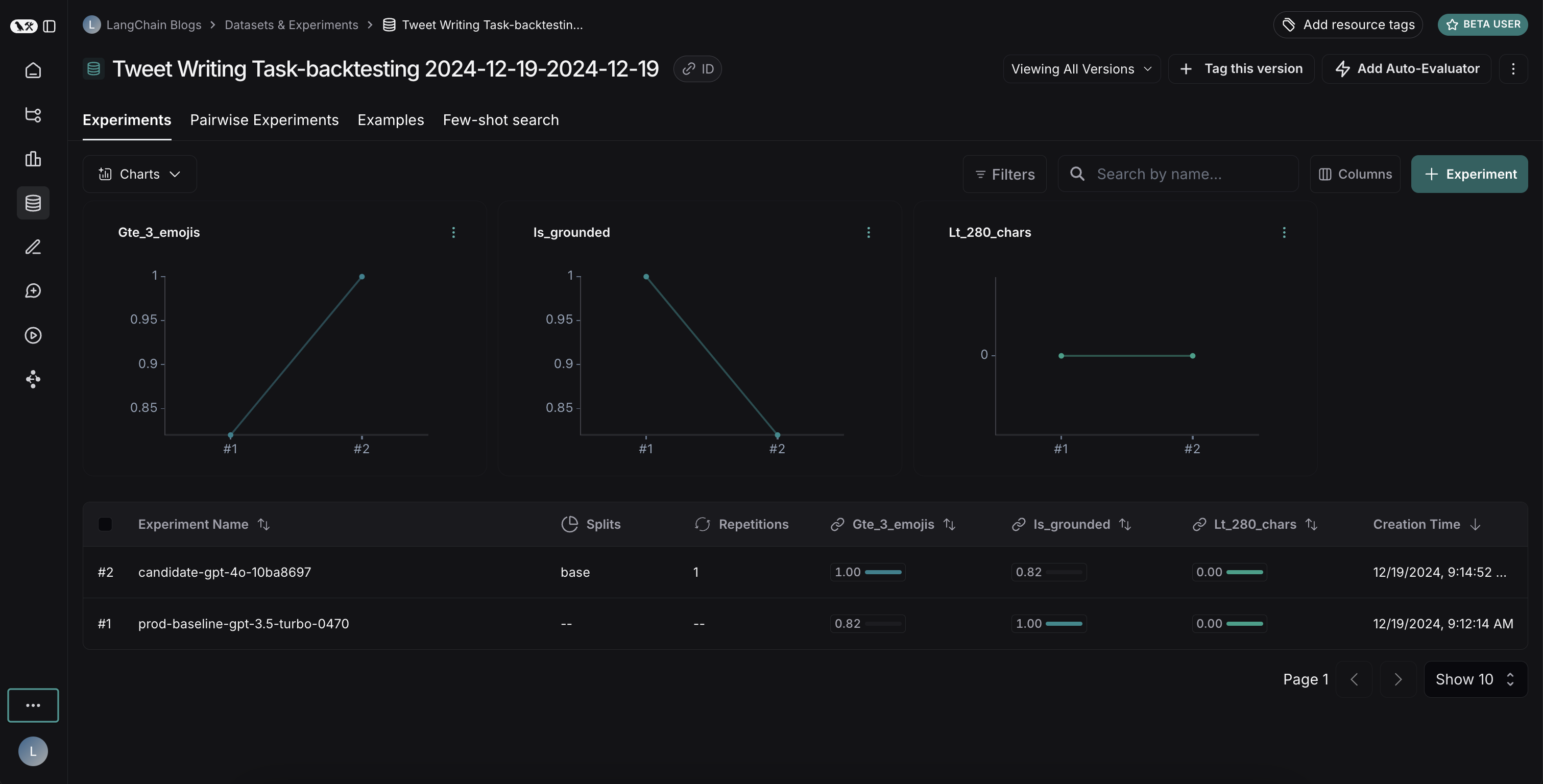 결과를 보면 두 모델 간의 흥미로운 트레이드오프를 확인할 수 있습니다:
결과를 보면 두 모델 간의 흥미로운 트레이드오프를 확인할 수 있습니다:
- GPT-4o는 형식 규칙을 따르는 성능이 향상되어 요청된 수의 이모지를 일관되게 포함합니다
- 그러나 GPT-4o는 제공된 검색 결과에 근거를 유지하는 면에서 신뢰성이 낮습니다
근거 문제를 설명하자면: 이 예제 실행에서 GPT-4o는 검색 결과에 없던 아부 바크르 무함마드 이븐 자카리야 알-라지의 의학적 기여에 대한 사실을 포함했습니다. 이는 제공된 정보를 엄격하게 사용하는 대신 내부 지식을 활용하고 있음을 보여줍니다.
이 백테스팅 작업을 통해 GPT-4o가 일반적으로 더 우수한 모델로 간주되지만, 단순히 업그레이드한다고 해서 트윗 작성기가 개선되지는 않는다는 것을 알 수 있었습니다. GPT-4o를 효과적으로 사용하려면 다음이 필요합니다:
- 제공된 정보만 사용하도록 프롬프트를 더 강력하게 강조하여 수정
- 또는 모델의 출력을 더 잘 제약하도록 시스템 아키텍처를 수정
이러한 통찰력은 백테스팅의 가치를 보여줍니다. 배포 전에 잠재적인 문제를 식별할 수 있었습니다.