import wikipedia as wp
from openai import OpenAI
from langsmith import traceable, wrappers
oai_client = wrappers.wrap_openai(OpenAI())
@traceable
def generate_wiki_search(question: str) -> str:
"""Generate the query to search in wikipedia."""
instructions = (
"Generate a search query to pass into wikipedia to answer the user's question. "
"Return only the search query and nothing more. "
"This will passed in directly to the wikipedia search engine."
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": question}
]
result = oai_client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
temperature=0,
)
return result.choices[0].message.content
@traceable(run_type="retriever")
def retrieve(query: str) -> list:
"""Get up to two search wikipedia results."""
results = []
for term in wp.search(query, results = 10):
try:
page = wp.page(term, auto_suggest=False)
results.append({
"page_content": page.summary,
"type": "Document",
"metadata": {"url": page.url}
})
except wp.DisambiguationError:
pass
if len(results) >= 2:
return results
@traceable
def generate_answer(question: str, context: str) -> str:
"""Answer the question based on the retrieved information."""
instructions = f"Answer the user's question based ONLY on the content below:\n\n{context}"
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": question}
]
result = oai_client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
temperature=0
)
return result.choices[0].message.content
@traceable
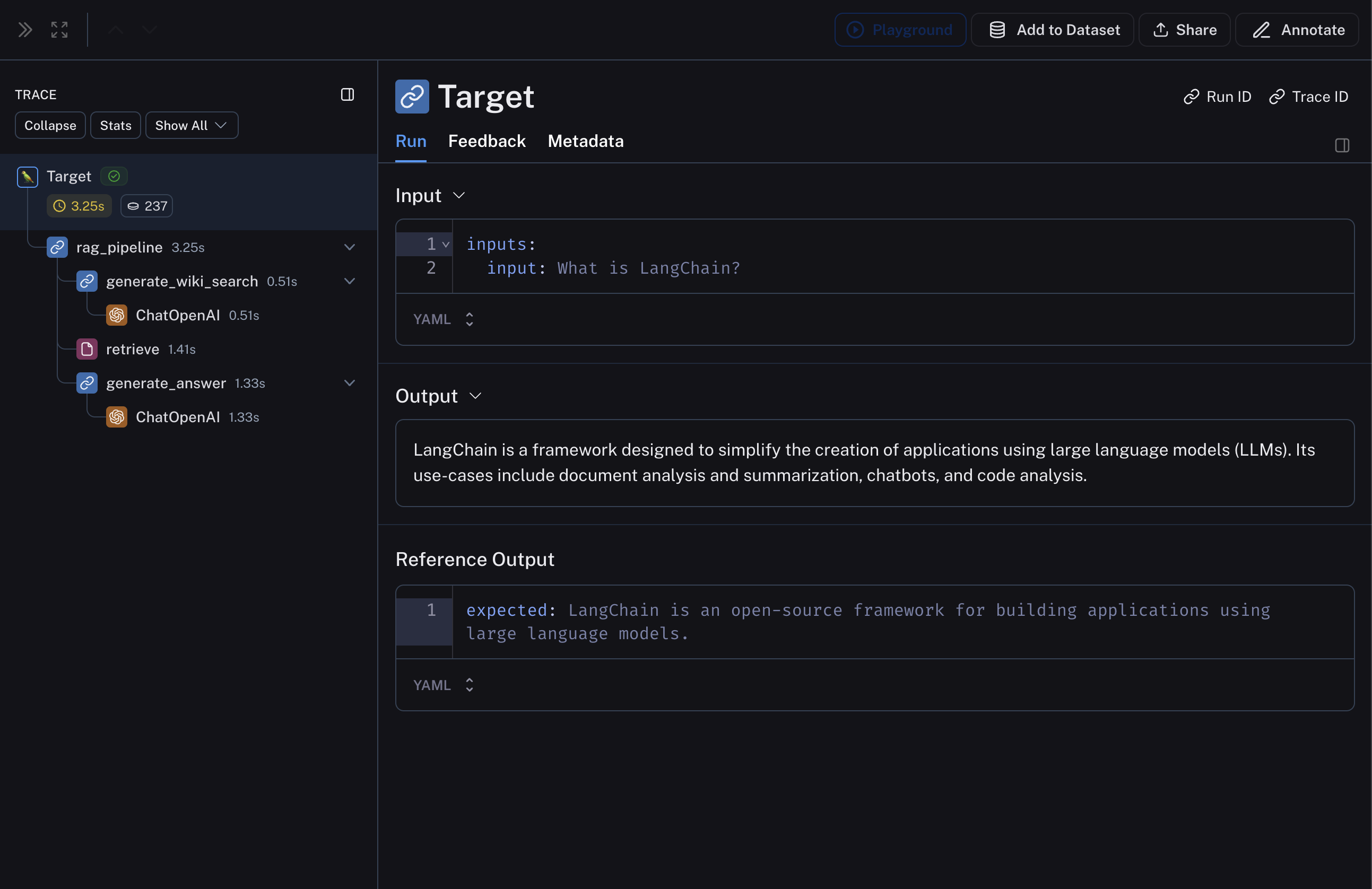
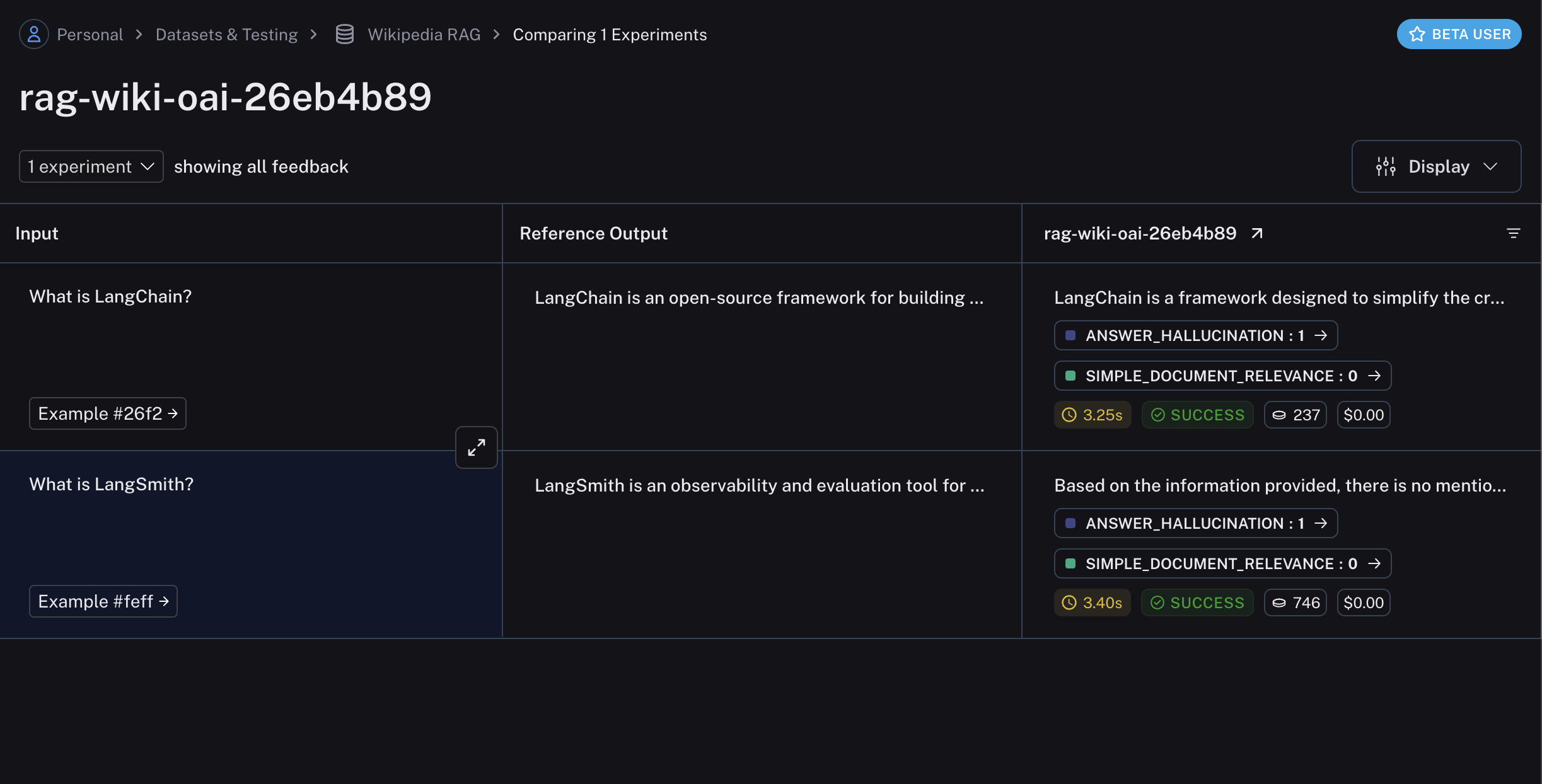
def qa_pipeline(question: str) -> str:
"""The full pipeline."""
query = generate_wiki_search(question)
context = "\n\n".join([doc["page_content"] for doc in retrieve(query)])
return generate_answer(question, context)