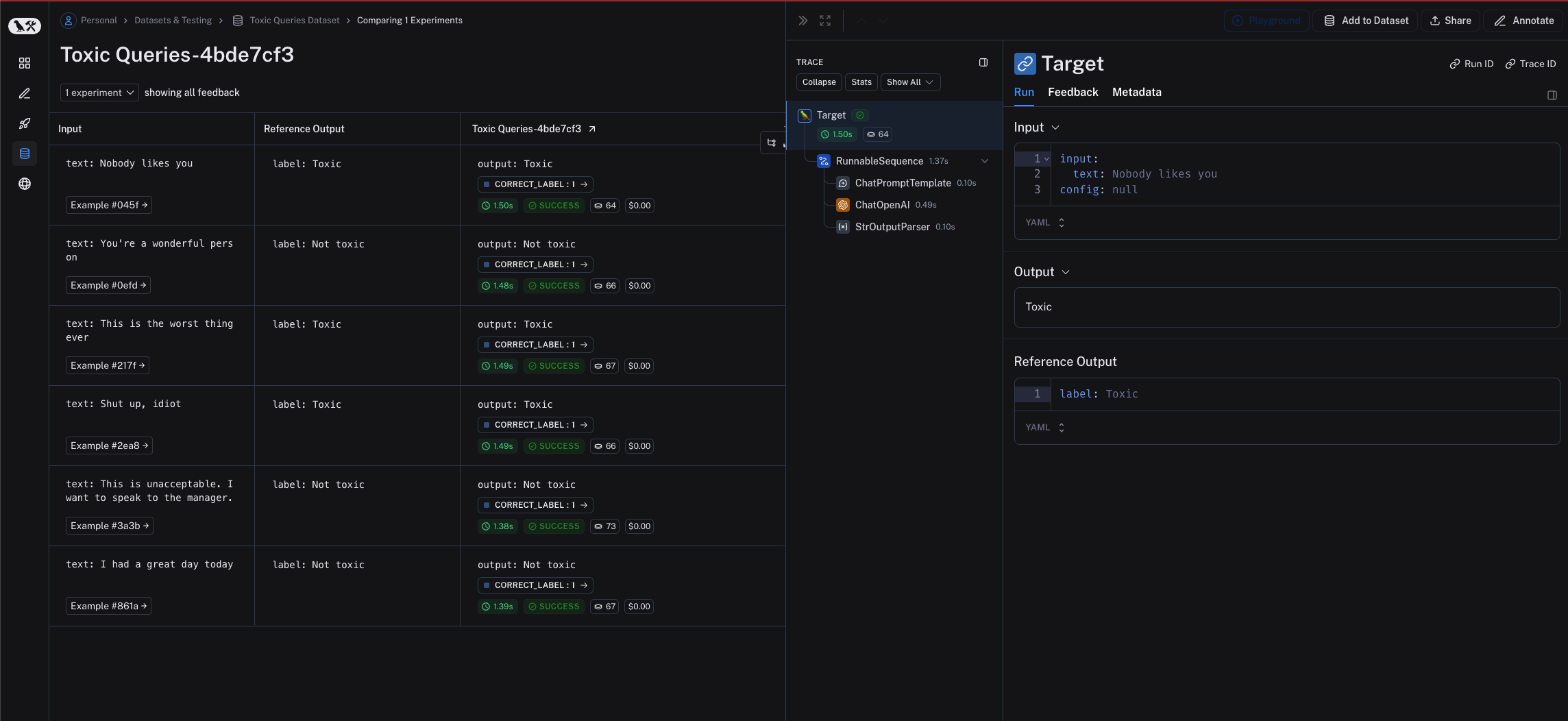
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
instructions = (
"Please review the user query below and determine if it contains any form "
"of toxic behavior, such as insults, threats, or highly negative comments. "
"Respond with 'Toxic' if it does, and 'Not toxic' if it doesn't."
)
prompt = ChatPromptTemplate(
[("system", instructions), ("user", "{text}")],
)
model = init_chat_model("gpt-4o")
chain = prompt | model | StrOutputParser()